
Analiza dyskryminacyjna – Wielowymiarowa analiza statystyczna klasyfikująca dla wielokategorialnych zmiennych zależnych.
Kierunkiem do jakiego dąży analiza dyskryminacyjna jest:
- Formalna logika jaką jest wzór funkcji dykryminującej mającej na celu wyszukanie miejsca do którego przystaje badany klient (lub inna jednostka zdefiniowana w badaniu) na podstawie pomiarów wykonanych na skali ilościowej (lub binarnej 0,1).
- Uzyskanie skomplikowanych prostych separujących grupy obiektów poddanych klasyfikowaniu
- Uzyskanie pakietu charakterystyk bezwzględnie najlepiej mogących opisywań różnice pomiędzy klasyfikowanymi grupami obserwacji.
LDA jest algorytmem statystycznym mającym na celu wyznaczenie wzoru, który będzie wzorem dyskryminującym lub klasyfikującym jednostkę badaną do zbioru grup „A” na podstawie zbioru pomiarów traktowanych jako zmienne niezależne. Analizę dykryminacyjną przeprowadza się na populacji treningowej, a następnie weryfikuję się jej trafność na zbiorze walidacyjnym (który nie brał udziału w trenowaniu analizy dyskryminacyjnej). Cenną uwagą w kontekście tej analizy jest to, że analityk wie z jakimi klasami obserwacji ma do czynienia oraz zna spektrum pomiarów jakie reprezentują te klasy.
Kroki konstruowania modelu Analizy Dyskryminacyjnej.
- Charakterystyka i selekcja pomiarów oraz podjęcie decyzji o ilości grup podlegających dyskryminacji.
- Próbkowanie dotyczące trenowania zbioru.
- Selekcja zmiennych w celu budowy funkcji dyskryminującej.
- Walidacja modelu na zbiorze testującym poprzednie kroki.
Krok 1.
- Charakterystyka pomiarów wyselekcjonowanych do analizy oraz podjęcie decyzji o ilości dyskryminowanych grup. d
- Selekcja pomiarów/charakterystyk może być przeprowadzona za pomocą eksploracji danych lub wstępnych badaniach statystycznych (mogą być również zasugerowane przez fachowca)
- Obserwacje w dyskryminowanych grupach muszą być niezależne. Ta sama jednostka badana nie może być przypisana do więcej niż jednej grupy badanej.
- Krok 2.
- Wylosowanie lub wybranie zbioru treningowego do przeprowadzenia analizy statystycznej metodą analizy dyskryminacyjnej.
- Rozdzielenie utworzonej próby na grupę treningową i zbiór walidacyjny.
- Krok 3.
- Wyznaczenie punktu dykryminacyjnego (próg odcięcia)
- Dla dwóch klas obiektów dobrym dyskryminatorem jest funkcja liniowa, dla więcej niż 2 klas warto zastanowić się nad wyborem metody asymptotycznej, Mahalanobisa lub kanonicznej.
- Krok 4.
- Wykonanie obliczeń na grupie treningowej w stosunku której jest jasne które jednostki badane przynależą do swoich klas.
- Jednostki badane znajdują swoje miejsce na zasadzie działania funkcji dyskryminacyjnej.
- Kierunkiem jaki może potencjalnie mieć analiza jest wyjaśnienie różnic między grupami lub ich klasyfikacja.
Wykonanie wzoru dyskryminacji.
Utworzenie podstawy i dyskryminacyjnej przedstawimy na przykładzie algorytmu (lub jak kto woli funkcji dyskryminacyjnej).
Podstawą do utworzenia funkcji dyskryminacyjnej jest założenie, że jednostki badane pochodzą z dwóch grup w których pomiary przyjmują rozkłady normalne, a w grupach tych są podobne wariancje-kowariancje między tymi zmiennymi. W ten sposób możemy określić formułę dyskryminującą
DF(x)=d1x1 + d2x2 + itd. Itd.
Dowolnie możemy manipulować poziomem odcięcia. Im wyższy wynik na skali DF tym obserwacja bardziej przynależy do którejś z grup, a im mniejszy jest tym obserwacja przynależy do drugiej grupy.
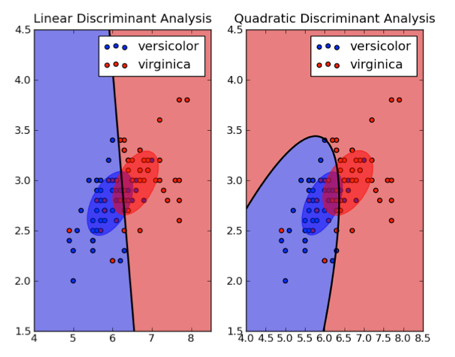
Jest to tak zwana dyskryminacja liniowa polegająca na liniowej kombinacji prostych rozdzielających klasyfikowane grupy. Do nauki włączył ją Ronald Fisher. Analiza dyskryminacyjna dąży do przyłożenia prostej, która najlepiej różnicuje obiekty (zakładając, że jako dystans będziemy interpretować wariancję wewnątrzgrupową). Analiza dyskryminacyjna jest bardzo skuteczną metodą jeśli chodzi o separację obserwacji do grup tylko i wyłącznie w przypadku kiedy założenia podstawowe są spełnione. Wiele symulacji wskazuje, że w przypadku dużych prób założenie o normalności rozkładów może być niespełnione, ale w przypadku innych założeń warte jest ich sprawdzenie i krytyczne odniesienie się co do stanu modelu (np. zastosowanie kwadratowej funkcji). Poza tym, że model dykryminacyjny separuje grupy to analiza dyskryminacyjna wskazuje wektory wpływów i ocenia siłę przyczynowo skutkowych zależności. W skrócie pomaga określić jakie zmienne mają wpływ dodatni, a jakie ujemny w perspektywie przynależności do wyodrębnionych klas.
Najważniejsze miary w analizie dyskryminacyjnej.
R – moc dyskryminacyjna ( przyjmuje wartości z zakresu 0-1). Im wyższy wynik wym większa porcja wariancji klasyfikowania jest wyjaśniana przez pomiary uwzględnione w modelu dyskryminacyjnym.
Lambda Wilksa l- Miara ta informuje o wariancji jaką wyjaśnia zmienna we wzorze dyskryminacyjnym grupy. W przypadku kiedy jest ona wysoka to znaczy, że dana zmienna ma słabą moc separującą. W przypadku niskiej jego wartości mamy do czynienia z podwyższoną porcją wyjaśnionej wariancji przez model dyskryminacyjny. Mamy wtedy do czynienia z lepszym modelem dyskryminacyjnym.
Odsetek poprawnych klasyfikacji – Dąży się do tego aby odsetek poprawnych klasyfikacji obserwacji do grup (jak we wszystkich metodach klasyfikacyjnych) był najmniejszy.