Analiza częstości występowania słów w R
Czas przejść do właściwego text miningu. Zaprezentujemy teraz procedurę pozyskania informacji o najczęściej występujących w tekście słowach oraz wykonania różnorodnych cloud of words w środowisku R.
3.1. Posiadając ujęte w tabeli wpisy z bloga Metodolog.pl, można przejść do wyodrębnienia pojedynczych słów z tekstu ciągłego. Dokonujemy tego za pomocą funkcji unnest_tokens.
Pożądanym wynikiem jest ramka danych przechowująca każde występujące w tekście słowo w osobnym wierszu. Aby nie zatracić możliwości analizowania danych pod kątem ich wystąpienia w konkretnym okresie, w ramce zachowujemy daną określającą czas, w którym słowo się pojawiło.
Aby określić, jak często pojawiły się w całości tekstu dane słowa, stosujemy funkcję count.
3.2. Uzyskaliśmy dane dotyczące występowania w tekście poszczególnych słów. Jak jednak łatwo sprawdzić (poniżej czynimy to za pomocą funkcji head), wszystkie 10 najczęściej występujących słów mogłyby znaleźć się w każdym tekście.
1 the 18283
2 of 11671
3 and 6152
4 to 5584
5 in 5387
6 a 4693
7 is 4293
8 that 2400
9 for 2005
10 are 1932
Nie niosą one żadnej informacji o specyfice wpisów analizowanych przez nas. Dzieje się tak, ponieważ pewne elementy języka – np. spójniki, czy – w języku angielskim – słowa „a” i „an”, „the” itp. – występują jako elementy gramatyczne niezależnie od charakteru treściowego tekstu. Nie są one interesujące w analizie, a z konieczności będą występować częściej od słów niosących treść, przez to posiadających dużo węższe zastosowanie.
Dlatego wszelkie takie nieprzydatne, a wręcz przeszkadzające w analizie tekstu słowa należy wykluczyć. To w tym momencie uprzednie przetłumaczenie wpisów na język angielski okazuje się przydatne. Dla angielskiego dostępne są specjalne słowniki zawierające słowa niepożądane – to tzw. stop words. W R słownik taki znajduje się w ramce stop_words dostępnej w pakiecie tidytext. Dzięki temu nie trzeba samodzielnie takich słów „wyłapywać”, wystarczy usunąć ze sporządzonego spisu słów te, które występują również w słowniku stop words. Przydatna w tym celu będzie funkcja anti_join, zwracająca w przypadku dwóch jednokolumnowych ramek danych różnicę zbiorów będących argumentami funkcji (w tym wypadku zbioru słów występujących w tekście oraz zbioru słów niepożądanych w analizie z ramki danych stop words).
Po wyeliminowaniu słów słowa najczęściej występujące w ogóle tekstów na blogu zmieniają się radykalnie i powiązane są z sektorem działalności Metodolog.pl. Krok ten umożliwił uzyskanie danych niosących pewne informacje, odzwierciedlających tematykę analizowanego tekstu.
1 statistical 1777 2 analysis 1587 3 data 1334 4 research 1170 5 results 822 6 variables 771 7 methods 643 8 model 642 9 variable 62210 test 601
3.3. Chociaż zwyczajne wyświetlenie (np. funkcją View) uzyskanej ramki danych może być najwygodniejszym i najdokładniejszym sposobem analizowania częstości występowania słów w tekście, to nie jest ono atrakcyjnym wizualnie sposobem przedstawiania wyników analizy. Z pomocą przychodzą tutaj tzw. chmury słów (ang. word cloud). Utworzenie chmury słów w R jest bardzo proste (choć może nie aż tak proste, jak w wyklikiwalnym Orange).
Potrzebny będzie nam pakiet wordcloud, w którym znajduje się interesująca nas funkcja wordcloud o składni:
wordcloud(words,freq,scale=c(4,.5),min.freq=3,max.words=Inf,
random.order=TRUE, random.color=FALSE, rot.per=.1,
colors=”black”,ordered.colors=FALSE,use.r.layout=FALSE,
fixed.asp=TRUE, …)
Jak widać, jako argumenty posłużyć mogą kolejne kolumny ramki uzyskanej przy pomocy funkcji count. Obligatoryjnie podać musimy, jakie słowa zilustrowane będą w chmurze słów i określić częstość ich występowania w tekście źródłowym (w oparciu o którą funkcja narysuje słowa o odpowiedniej wielkości). Warto skorzystać także z możliwości wybrania liczby słów, które zostaną wyświetlone (parametr max.words) oraz zrezygnować z losowej kolejności wyświetlania słów w celu uzyskania wyższej klarowności generowanego obrazka (parametr random.order). Analizę obrazka ułatwi, zarazem podnosząc jego atrakcyjność wizualną, uczynienie słów kolorowymi (poniżej używany do tego jest pakiet RColorBrewer). Przykładowo:
require(RColorBrewer)
wordcloud(count(slowa, slowo)$word, count(slowa, slowo)$n, max.words = 200, colors = brewer.pal(8, „Dark2”), random.order = F)
Uzyskane chmury słów stanowią efektowny sposób prezentacji wyników analizy. Poniżej zostają zaprezentowane chmury utworzone przed i po usunięciu słów ujętych w słowniku stop_words. Ich porównanie świetnie pokazuje, że przed wyeliminowaniem niepożądanych słów wyniki były praktycznie bezwartościowe.
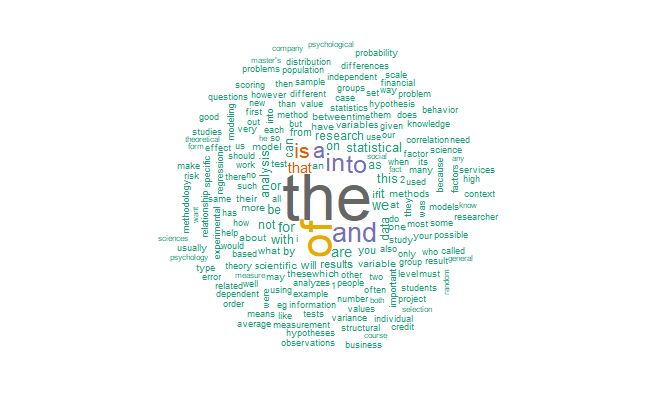

3.4. Mimo że druga chmura słów prezentuje się nieporównywalnie lepiej od pierwszej i przekazuje konkretne informacje, to jednak uważny obserwator bez trudu zauważy w niej elementy, których lepiej byłoby się pozbyć – chodzi o cyfry. Nie posiadają one poza kontekstem żadnego sensu, a to, że na blogu statystycznym występują cyfry, jest oczywistością. Dlatego dodatkowo usuniemy z tekstu cyfry oraz inne uprzednio zidentyfikowane elementy tekstowe, możliwe do prostego zidentyfikowania, które w żaden sposób nie nadawały się do analizy.
blokada <- c(„r”, „t”, „ax”, „ml”, „lb”, „b”, „pg”, „ab”, „cg”, „k”, „id”, „rm”, „ad”, „fa”, „st”, „pp”, „pi”, „6”, „3”, „4”, „c”, „bf”, „cl”, „ht”, „kt”, „cm”, „gm”, „0”, „kg”, „ti”, „gt”, „iv”, „l”, „f”, „hr”, „-1”, „ma”, „ha”, „7”, „xi”, „ch”, „it”, „1”, „m”, „8”, „9”, „2”, „km”, „em”, „tn”, „ta”, „e”, „bi”, „ed”, „wk”, „dc”, „ii”, „5”)
blokada <- data.frame(blokada)
colnames(blokada) <- “slowo”
slowa <- anti_join(slowa, blokada)
3.5. Rzadko kiedy zależy nam na zachowaniu dokładnej formy gramatycznej analizowanych słów. Wręcz przeciwnie – w pewnych wypadkach nadmierna czułość rozróżnienia będzie wpływała na trudności w analizie częstości występowania słów. Świetnie widać to w języku polskim – np. odmienność słów „statystyczny” i „statystyczna” nie wynika w żadnym stopniu z odmienności znaczenia. W innych językach również będą występować takie sytuacje, a w analizie statystycznej nadmierna dokładność bywa zwyczajnie niepożądana (np. utrudniająca osiągnięcie prawidłowych konkluzji, a niedająca nic w zamian).
Z tych względów w text miningu stosuje się tzw. stemmery. Pozwalają one na ujednolicanie słów zbliżonych znaczeniowo, choć odmiennych gramatycznie. Stemmery mogą działać w sposób skomplikowany bardziej (np. Snowball) lub mniej (np. Hunspell). Zależnie od charakteru analizy, zależeć może nam na maksymalnym ujednoliceniu słów (czyli zachowaniu tylko ich trzonu znaczeniowego lub części słowa pozwalającej na określenie tego trzony) lub uzyskaniem trochę większej dokładności, objawiającej się choćby rozróżnianiem rzeczowników od odpowiadających im przymiotników.
Poniżej zaprezentowano dziesięć najczęściej występujących słów oraz chmurę słów po użyciu stemmera Hunspell. Warto zwrócić uwagę na to, że bardziej ogólne formy pewnych słów „wchłonęły” swoje szczególne formy, przez co wśród najczęściej spotykanych słów pojawiły się wcześniej niewystępujące. Nowo utworzona chmura słów najlepiej oddaje rzeczywisty charakter wpisów, które pojawiły się na stronie.
1 statistical 1834
2 analysis 1588
3 variable 1393
4 data 1334
5 search 1321
6 method 1101
7 result 1088
8 test 986
9 model 925
10 study 636

3.6. Poniżej zaprezentowany zostaje przykładowy, krótki kod, za pomocą którego można zacząć swoją przygodę z text miningiem. Zakładamy, że dane zostały wczytane jako obiekt data, a tekst wszystkich wpisów przechowywany jest w kolumnie Tekst.
#podzial tekstu na pojedyncze slowa
slowa <- unnest_tokens(select(data, Numer, Tekst), slowo, Tekst)
#przeliczenie slow i uszeregowanie w kolejności od występujących najczesciej
count(slowa, slowo, sort = T)
#usuniecie slow stop words z ramki slow i przypisanie przeliczenia do zmiennej
slowa <- anti_join(slowa, stop_words)
liczebnosc <- count(slowa, slowo, sort = T)
#narysowanie chmury slow
wordcloud(liczebnosc$slowo, liczebnosc$n, max.words = 100)
Analizy oraz wpis sporządził Pan Andrzej Porębski. Dziękujemy!