Wielu badaczy jest przekonanych, że modelowanie równań strukturalnych jest związane zazwyczaj z analizą statystyczną właściwości statystycznych narzędzi pomiarowych (tzw. Konfirmacyjna analiza czynnikowa), modeli wielowymiarowych, modeli mediacyjnych, moderacyjnych lub mieszaniny tych dwóch ostatnich. Niemniej, jest wiele specyficznych modeli równań strukturalnych które są zorientowane w kierunku specyficznych celów modelarskich np. Modele wzrostu zmiennej latentnej (ang. Latent Growth Models), autoregresyjna ukryta trajektoria struktury reszt (ang. Autoregressive Latent Trajectory Model with Structured Residuals), model podwójnej zmiany (ang. Dual Change Score Model) i wiele innych. Wszystkie te modele odpowiadają na różne pytania i rozluźniają pewne założenia zawarte w strukturze danych.Przykładowo, Kross lagowy model panelowy z efektami losowych stałych (ang. Random Intercepts Cross Lagged Panel Model ) rozluźnia założenie statystyczne które dotyczy wewnątrzosobniczych efektów powiązań między zmiennymi. Model ten pokazuje, że stabilność mierzonych konstruktów ma do pewnego stopnia podobieństwo do ludzkiej cechy, która ma niezmienną czasowo naturę (przynajmniej w trakcie trwania pomiarów w trwającym badaniu). Klasyczny model kros lagowy (ang. Cross Lagged Panel Model) nie uwzględnia tej okoliczności i pozwala oszacować jedynie model odzwierciedlający efekt populacyjny.
Wykazywanie przyczynowości w modelu powtarzanych pomiarów?
Panelowe modele kros lagowe oraz kross lagowy model panelowy z efektami losowych stałych (ang. Cross Lagged Panel Model and Random Intercepts Cross Lagged Panel Model) to metody analiz statystycznych które pozwalają na oszacowanie, albo rozstrzygnięcie, efektów przyczynowo-skutkowych w układach badań o charakterze powtórzonych pomiarów. Takie badanie jest jedyną metodą nieeksperymentalną która pozwala na wyciągnięcie silnych wniosków na temat przyczyn (podobnie silnych jak w przypadku badań eksperymentalnych w których testujemy przyczynę w grupie eksperymentalnej i jej brak w grupie kontrolnej). Wspomniane wyżej modele statystycznesą bardzo popularne w psychologii (szczególnie rozwojowej), marketingu, zarządzaniu oraz zdrowiu publicznym. Ogólnie są dobre wszędzie tam gdzie wywołanie przyczyn eksperymentalnie jest z jakichś względów niemożliwe (np. jest nie etyczne lub drogie). Modele kros lagrowe (ang. Cross Lagged Panel Model) są znane od lat 80), aczkolwiek pojawiła się krytyka tych modeli w roku 2015 (Hamaker, 2015). W tym typie dowodzenia przyczynowości możemy już w przypadku dwóch powtórzonych pomiarów rozstrzygnąć jaka zmienna jest przyczyną, a jaka skutkiem. Taki kross-lagowy model możemy zbudować dzięki bibliotece “lavaan” języka R lub w Plusie. Ten ostatni pozwala na testowanie bardzo wyrafinowanych oszacowań. Ogólnie dzięki tym modelom, a także metodologii powtarzanych pomiarów możemy odpowiedzieć w ciekawy sposób na nastepująca pytanie badawcze: Czy agresja rodziców wpływa na agresję dzieci? Czy może jest odwrotnie?
Jak klasyczny panelowy model kros lagowy (Cross Lagged Panel Model) może odpowiedzieć na powyższe pytanie?
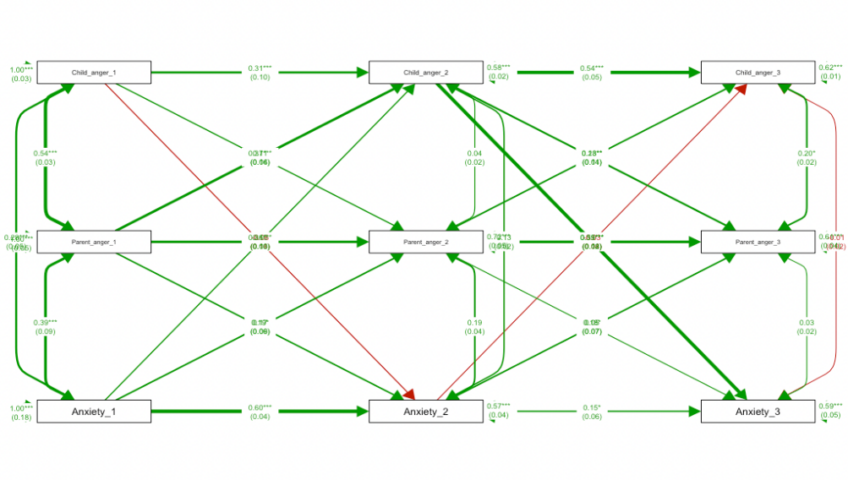
Jeśli pozwolimy sobie na obserwacje agresji w diadach (rodzic i dziecko) pod względem przejawów agresji, to możemy zebrać informacje o dwóch źródłach zmienności wyników. Pierwsze to rodzic t1 -> rodzic t2, and dziecko t1 -> dziecko t2 (autoregresyjny element modelu), a drugie to rodzic t1 -> dziecko t2 and dziecko t1 -> rodzic t2 (kros lagowy element modelu). Jeśli zbudujemy sobie model techniką modelowania równań strukturalnych w duchu modelu kroslaggowego, to będziemy mogli ocenić co dzieje się w naszych wynikach nieeksperymentalnego eksperymentu. Jeśli nasze auto regresyjne elementy modelu są istotne, to znaczy, że nasze obserwowane efekty czasowe są istotne, czyli, że agresja obu stron jest ze sobą powiązana między pomiarami. Aczkolwiek, jeśli ścieżka rodzic t1 -> dziecko t2 jest istotna (lub ma silniejszy efekt niż przeciwna ścieżka) wtedy przyczyny agresji dzieci w t2 można przypisać agresji rodziców w t1. Niemniej, jeśli ścieżka dziecko t1 -> rodzic t2 jest również istotna (i ma podobną siła jak ścieżka wspomniana wcześniej), to wtedy rezultat naszego nieeksperymentalnego eksperymentu jest niekonkluzywny. Jest to klasyczny przykład struktury danych która pozwala na wyciągnięcie przyczynowych wniosków z tego typu modelowania. Oczywiście, w takich układach możemy wyciągać więcej wniosków np. możemy oszacować efekty mediacyjne (ang. Cross lagged madiation effects), gdzie komponenty mediacyjne (x t1 -> m t2 (ścieżką mediacji a) m t2 -> y t3 (ścieżka mediacji b) są wyliczane w kolejno wykonanych trzech powtórzonych pomiarach. Taki model prezentuje na rysunku nr 1.
Rysunek 1
Klasyczny panelowy model kros lagowy z efektem mediacji
(Ang. Classical Cross Lagged Panel Model examining mediation longitudinally)
Jak na to samo pytanie badawcze odpowiada panelowy model kros lagowy efektów losowych stałych (ang. Random Intercepts Cross Lagged Panel Model)?
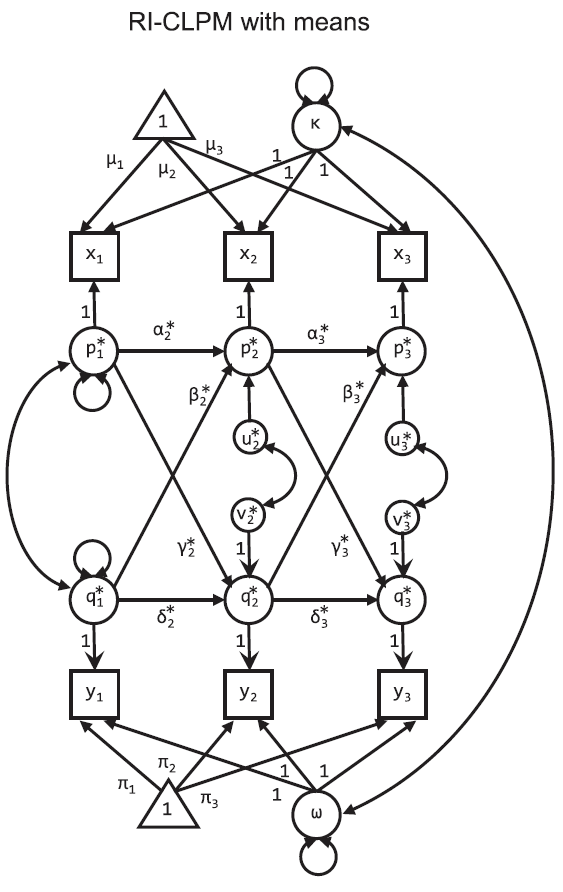
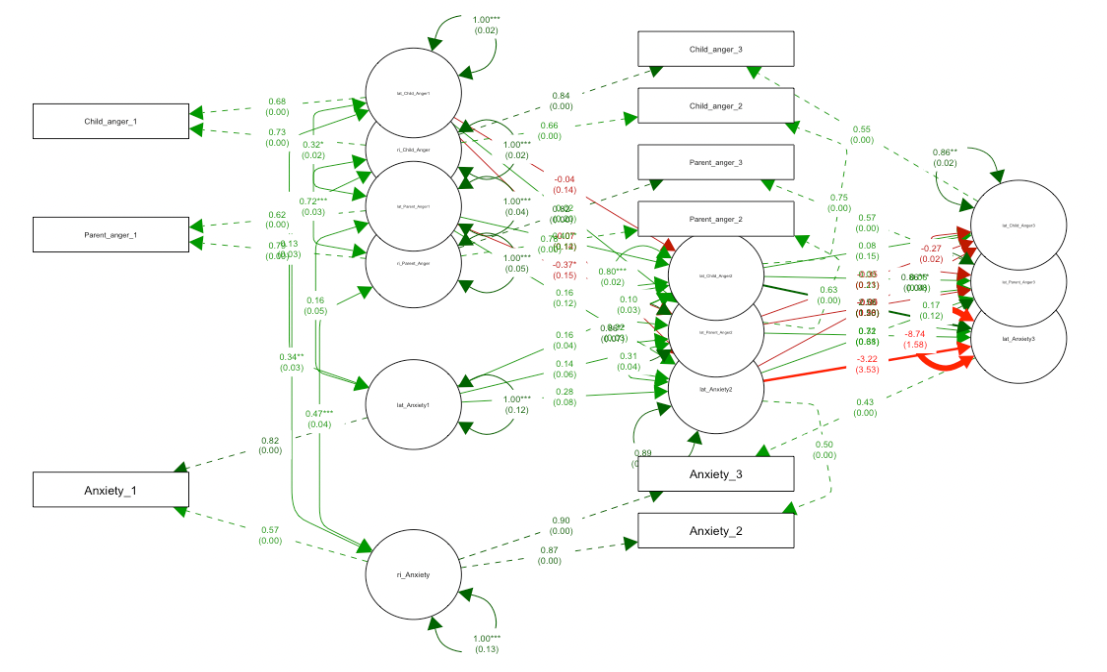
Powróćmy do naszego pierwotnego pytania: Czy agresja rodziców wpływa na agresję dzieci? Czy może jest odwrotnie? Jeśli chodzi o odpowiedź na to pytanie dzięki modelowi losowych stałych, możemy w nim oszacować tzw. wewnętrzobiektowy efekt przeniesienia (ang. within carry over effect). Efekt ten jest nie podobny do modelu within w regresji panelowej. Ogólnie możemy się zgodzić, że powtarzane pomiary możemy traktować jako dane o strukturze wielopoziomowej, czyli, że pomiary t1, t2, t3 itd. cech są zagnieżdżone w osobach. W takich okolicznościach jest konieczne oddzielenie efektu zmienności wyników na poziomie wewnątrz obiektowym (within) od efektu między obiektowego (between). Random Intercepts Cross Lagged Panel Model dekomponuje obserwowane wyniki w dynamikę wewnątrz jednostkową oraz stabilne różnice pomiędzy badanymi obserwacjami. Taka sytuacja musi być specyficznie “odkodowana” w syntaksie budującym model strukturalny.
Dalej, czasowa stabilności w takich okolicznościach musi być traktowana jako cecha (założenie wewnętrzosobowej stabilności czasowej wyników) poprzez wprowadzenie losowego efektu interceptów. Strukturalnie jest to przeliczane poprzez odchylenie danej obserwacji od średniej populacyjnej. W takich okolicznościach współczynniki autoregresyjne modelu (te x t1 -> x t2) oraz efekty kross lagowe reprezentują wspomniany efekt przeniesienia (ang. within carry over effect). Pozytywne wartości ścieżek wyrażają to, że kiedy osoba ma wynik powyżej wartości oczekiwanej (średniej populacyjnej) przy pomiarze 1 to w pomiarze 2 jest również prawdopodobne to, że ma wynik powyżej wartości oczekiwanej (średniej populacyjnej). Niemniej, efekty kross lagowe i ich oszacowania wyrażają to jak wartość poniżej albo powyżej wartości oczekiwanej w zmiennej x t1 wpływa na wartość poniżej lub powyżej wartości oczekiwanej na y2 (oczywiście przy jednoczesnej kontroli efektu autoregresyjnego). Może się to wydawać nieco skomplikowane, ale żeby to lepiej zrozumieć trzeba przestawić myślenie z rozumowania o efekcie populacyjnym na myślenie o indywidualnym efekcie przeniesienia. Tłumacząc te wyjaśnienia w nasz problem badawczy agresji dzieci i rodziców możemy powiedzieć, że agresja obu obiektów obserwacji może być traktowana jako czasowo niezmienna np. agresja dziecka x jest o 3 jednostki wyższa od średniej w 1 pomiarze, natomiast jest też wyższa o 3 jednostki w drugim i trzecim pomiarze. Ten efekt odchyleń jest kontrolowany zarówno u dzieci i rodziców w przypadku agresji u jednych i drugich (efekt autoregresyjny), a także ich wzajemnych wpływów (efekt cross laggowy)
Rysunek 2
Panelowy model kros lagowy z efektem losowych interceptów
Cześć! Dzięki, że kliknełeś/aś ten link! Będę Ci niesamowicie wdzięczny za wypełnienie mojej ankiety do pracy naukowej! Pracujemy w zespole nad bardzo ciekawym problemem związanym z marketingiem i psychologią.
Każda ankieta jest dla nas bardzo ważna, dlatego jeśli znasz kogoś kto lubi je wypełniać, to będziemy wdzięczni za pomoc 🙂
Poniżej znajduje się link do ankiety:
Link do ankiety klik lub do przeklejenia w przeglądarkę http://kanonpojecpsychologicznych.pl/lime/index.php/262786?lang=pl
Autorski test osobowości HPTI (Hryniewicz Personality Type Inventory) wzorowany na teście MBTI
Ze względu na to, że nasz jeden klient nie opłacił rachunku za zakup testu osobowości na potrzeby jego celów biznesowych, wrzucamy go tutaj dla wszystkich 🙂 Test ten jest wzorowany na teorii MBTI i konstruktach specyfikowanych w tym ujęciu teoretycznym. Zachęcamy do korzystania. W celach naukowych poniższy test jest darmowy i wyrażamy zgodę na korzystanie z niego. Podkreślamy jednak, że test nie przeszedł jeszcze walidacji psychometrycznej i jego właściwości pomiarowe nie są znane. Zachęcamy do kontaktu osoby zainteresowane jego wykorzystaniem w celach naukowych i biznesowych.
1. Ekstra
1
Lubię towarzystwo innych i wszechobecną energię
2
Odżywam dopiero w towarzystwie ludzi
3
Szybko nawiązuje znajomości i zdobywam sympatie ludzi
4
Ciężko mnie zranić
5
Wolę iść na festiwal niż oglądać go w TV lub internecie
6
Lubię poznawać energicznych i szalonych ludzi
7
Rzadko przeżywam negatywne emocje
8
Nie przepadam za towarzystwem smutasów
9
Jestem na co dzień ekspresyjną i wesołą osobą
10
Nie potrafię długo usiedzieć w jednym miejscu
11
Często zachowuję się beztrosko
12
Ciągle poszukuję ludzi którzy zapewnią mi silne doznania
13
Szybko skracam dystans do nieznajomych ludzi
14
Trzymam się z ludźmi którzy są energiczni i aktywni jak ja
15
Nie cierpię przebywać w samotności
2. Intro
1
Jestem zamkniętą na innych, cichą i ceniącą sobie spokój
2
Jestem osobą która w jest małomówna
3
Nie lubię zwracać na siebie zbytniej uwagi
4
Na przyjęciach trzymam się gdzieś z boku
5
Jestem kimś kto długo przekonuje się do innych
6
Zazwyczaj potrzebuję dużo spokoju i ciszy
7
Mam bogatsze życie wewnątrz „Ja” niż na zewnątrz
8
Mam głębokie relacje tylko z kilkoma osobami
9
Wolę skromne towarzystwo niż duże imprezy
10
Nie czuję się dobrze jeśli wiele się wokół mnie zmienia
11
Często chcę coś powiedzieć, ale w końcu nie mówię
12
Nie przepadam za głośnymi osobami
13
Niechętnie okazuję uczucia
14
Czuję większy dystans przed obcymi osobami niż inni ludzie
15
Dłużej nawiązuję nowe znajomości niż większość ludzi
1. Sensing
1
Cenię ludzi myślącymi bardziej konkretnie niż abstrakcyjnie
2
Jestem osobą która woli jasne i konkretne kryteria ocen
3
Lubię kiedy inni traktują mnie jako osobę rozsądną, a nie uczuciową
4
Nie lubię kiedy ludzie dają mi niepełne lub niedokładne informacje
5
Wolę zapoznawać się z faktami i dowodami niż poglądami teoretyków
6
Otaczam się ludźmi którzy w swoim działaniu posługują się schematami
7
Jestem kimś kto woli być pewny niż mieć jakieś przeczucia
8
Wolę spędzać czas z „realistami” niż „filozofami”
9
Nie biorę marzycieli za dobrych partnerów do współpracy
10
Wolę sprawdzone sposoby działania niż wymyślanie własnych
11
Intensywnie rozmyślam o innych ludziach i wszechświecie
12
Cenię bardziej ludzi mających „głowę na karku” niż artystów
13
Bazuję na liczbach i faktach niż na poglądach innych
14
Zawsze organizuję każde informacje
15
Zupełnie nie wierzę się w plotki o innych osobach
2. Intuition
1
Lubię w innych ludziach ekspresję magii lub ekscentryzmu
2
Moja wiedza życiowa jest budowana na intuicji, kojarzeniu i emocjach
3
Jestem osobą której serce wskazuje dobrą drogę w życiu
4
Lubię ludzi którzy posługują się metaforami i barwnym językiem
5
Wolę przyjaźnić się z osobami „czującymi” niż „rozumiejącymi” świat
6
Mam więcej przyjaźni z ludźmi kierującymi się w życiu uduchowieniem
7
Podążam za swoimi przeczuciami i zawsze się w nie głęboko wsłuchuję
8
Często wizualizuję sobie w umyśle barwny świat własnych doświadczeń
9
Uwielbiam osoby kieruące się emocjami niż myśleniem
10
Lubię i podziwiam w ludziach ich artystyczny nieład
11
Zawsze w chaosie zachowania innego człowieka widzę jakiś głębszy sens
12
Trzymam się ludźmi którzy mają bardziej „romantyczny” pogląd na świat
13
Zguby szukam kierując się doznaniami i wyczuciem otoczenia
14
Czuję spokój kiedy coś jest wieloznaczne, a nie czarne lub białe
15
Odbieram życie doznaniowo i mam szeroką perspektywę na innych
1. Thinking
1
Myślę, że tylko myślenie logiczne i zasady pozwalają dobrze żyć
2
Wierzę, że sprawiedliwość jest ważniejsza od mołośerdzia
3
Działam, by zasady były przestrzegane, często kosztem dobra innych ludzi
4
Nie biorę pod uwagę krzywd innych jeśli chodzi o przestrzeganie norm
5
Lubię ludzi potrafiących przeciwstawić się innym ludziom
6
Jestem osobą konsekwentną, czasem na przekór innym ludziom
7
Przyjaźnię się w większości z ludźmi którzy są szczerzy do bólu
8
Zawsze działam przemyślanie i sprawiedliwe
9
Jestem bardziej osobą bezstronną niż wielkoduszną
10
Myślę, że ludzie każdym przypadku powinni kierować się sprawiedliwością
11
Nie czuję urazy jeśli ktoś jest zbyt szczery
12
Wolę być osobą kompetentną niż współczującą innym
13
Współpracując z innymi jestem osobą bardziej rzetelną niż ciepłą
14
Często w imię zasad wyrządzam komuś przykrość
15
Wierzę, że dobra decyzja często musi naruszać dobro innych ludzi
2. Feeling
1
Moja intuicja i przeczucia są kluczowe przy podejmowaniu decyzji
2
Jestem osobą która bardziej dba o uczucia ludzi niż ich prawa
3
Czuję, że do pewnego stopnia przewiduję wydarzenia w przyszłości
4
Uważam, że kryteria ocen są krzywdzące dla osób ocenianych
5
Kiedy podejmuję decyzję, to zawsze biorę pod uwagę dobro innych ludzi
6
Jestem osobą taktowną i nigdy nie mówię „zimnej” prawdy innym ludziom
7
Mocno dbam o życie z ludźmi w harmonii i czuję niepokój gdy jej brakuje
8
Nie lubię ranić innych mówiąc im to co naprawdę myślę lub czuję
9
Często zachowuję się w stosunku do innych kierując się współczuciem
10
Myślę, że ludzie w każdym przypadku powinni kierować się miłosierdziem
11
Przyjaźnię się z ludźmi miłymi, którzy zawsze dbają o dobro innych
12
Jestem osobą która jest zawsze zorientowana dobrostan innych osób
13
Troszczę się o to by się dobrze czuli
14
Często poświęcam siebie by inni poczuli się miło
15
Ważniejsze dla mnie jest kierowanie się w życiu sercem niż zasadami
1. Judging
1
Moje życie jest planowane w bardzo drobnych szczegółach
2
Jestem osobą która posługuje się tylko faktami, danymi i liczbami
3
Wierzę, że mój sukces zależy od trzymania się algorytmów i metod
4
Zawsze opracowuję plany realizacji swoich celów i marzeń
5
Jeśli coś zgubię, to systematycznie tego szukam
6
Niepokoję się kiedy coś w mojej pracy jest nieuporządkowane
7
Bardziej lubię tradycyjne potrawy niż nowe np. kuchni „fusion”
8
Lubię robić dokładne listy zakupów lub rzeczy do zrobienia
9
Muszę mieć skończoną pracę zanim przejdę do przyjemności
10
Planuję pracę tak by uniknąć pośpiechu przed ustalonym terminem
11
Lubię osoby mające wyraźne plany i stabilność w ich realizacji
12
Cenię w ludziach zaangażowanie we wspólne organizowanie czegoś
13
Jestem człowiekiem zorganizowanym lepiej niż inni ludzie
14
Wolę trzymać się z osobami „ułożonymi” niż spontanicznymi
15
Zawsze metodycznie działam zgodnie ze swoimi pierwotnymi założeniami
2. Perceiving
1
Nie lubię korzystać z instrukcji, schematów i procedur
2
Jestem osobą otwartą reaguję euforycznie na nowe wydarzenia
3
Bardziej mnie motywuje zbliżający się termin niż harmonogram prac
4
Jestem osobą która realizuje zadania tylko wtedy gdy ma poczucie „flow”
5
Plan nie da mi tyle w pracy co emocje i pozytywne nastrojenie się
6
Do współpracy wybieram osoby spontaniczne i nieszablonowe
7
Nie widzę korzyści w korzystaniu z planerów i kalendarzy
8
Nie podoba mi się organizowanie i kontrolowanie swojego życia
9
Bardzo cenię sobie elastyczny i spontaniczy styl życia
10
Trzymam się z ludźmi którzy też mają nieco niezorganizowany tryb życia
11
Bardziej dostosowuję się do wymagań życia niż je organizuję
12
Ludzie widzą mnie jako osobę otwartą na nowe doświadczenia
13
Czuję miły i pociągający dreszczyk przed nieszablonowym działaniem
14
Bardziej lubię osoby które lubią podejmować ryzyko niż osoby roztropne
15
Jestem osobą która ma złożony sposób postrzegania świata
Powyższy test jest chroniony prawami autorskimi. Więcej informacji udzieli mgr Konrad Hryniewicz.
Poniżej przedstawiamy jedno ze szkoleń statystycznych które przygotowaliśmy dla pracowników naukowych uniwersytetu ***. Kod jest zapisany w R Markdawn.
—
title: „*Szkolenie z modelowania wielopoziomowego w R*”
author: „mgr Konrad Hryniewicz – Metodolog.pl”
date: „`r format(Sys.time(), ‚%d %B, %Y’)`”
output:
rmarkdown::html_document:
theme: cerulean
toc: true
toc_float: true
—
**Rozwiązanie dostarczone przez Metodolog.pl**
*spec. ds. Analiz Statystycznych, Metodologii Badań oraz języka R*
library(„openxlsx”)
library(„dplyr”)
library(„ggplot2”)
library(„tidyverse”)
library(„Hmisc”)
library(„writexl”)
library(„car”)
library(„kableExtra”)
library(„lme4”) # MLM
library(„lmerTest”) # Statytyki diagnostyczne dla MLM
library(„jtools”) # Wyswietlanie eleganckich wydrukow dla modeli regresyjnych w tym MLM
library(„merTools”)
library(„sjPlot”) # Wyswietlanie eleganckich tabel dla modeli regresyjnych w tym MLM
setwd(„…”) #funkcja ustaljaca folder roboczy ze wszystkimi plikami
mydata = openxlsx::read.xlsx(„sen.xlsx”) #funkcja otwierająca plik xlsx z dysku
write.xlsx(mydata, „nowe_dane.xlsx”) #funkcja zapisujaca ramki danych w formacie xlsx
options(scipen = 160) #nikt nie lubi notacji naukowych wiec chcemy wiedzieć w wynikach dużo miejsc po przecinku
set.seed(12345678) #ustalamy ziarno pseudolosowania by wystandaryzowac wyniki analiz
colnames(mydata) # patrzymy jakie mamy nagłówki kolumn
„`
## **Wstęp – Jakie są założenia OLSM i dlaczego są one bardzo często trudne do utrzymania w praktyce badawczej? ** ##
1. Model klasycznej liniowej analizy regresji zakłada (a także większość modeli statystycznych), ze wyniki obserwacji są od siebie niezależne np. mój wzrost nie zależy od Twojego wzrostu.
2. Nachylenia linii regresji np. dotyczące zależności miedzy waga a wzrostem są podobne w podgrupach zmiennej grupującej np. płci, grup zawodowych itp.
3. Zjawisko analizowane na ogólniejszym poziomie może być pewnym „złudzeniem”, czyli tzw. Paradoksem Simpsona mówiące o tym, że zjawiska rozpatrywane fragmentarycznie różnią się od zjawiska rozpatrywanego ogólniej.
ad1. W praktyce badawczej te założenia są często ciężkie do spełnienia np. moja ocena z matematyki może być zależna od ocen mojego kolegi/koleżanki z ławki np. dlatego, że ma ojca który poświęca mu/jej dużo czasu na wspólne uczenie się i ta osoba powiela ten schemat wobec mnie 🙂
ad2. Zależność między potencjałem kulturowym nauczyciela może wiązać się z ocenami dzieci z historii różnie w różnych klasach danej szkoły. W jednej klasie może wpływać silniej, a w drugiej słabiej, ale nadal pozytywnie. W trzeciej natomiast, może wpływać, z jakichś względów oczywiście, bardzo silnie, a w czwartej bardzo słabo, dlaczego? Nie wiadomo, ale wiadomo, ze źródłem tej zmienności może być po prostu nauczyciel historii posiadający jakiś konkretny losowy mix cech.
ad3. To trzeba zobaczyć na własne oczy.
## **Jak możemy modelować zjawiska dzięki modelowaniu wielopoziomowemu?** ##
**Zwykła analiza regresji**
**Indywidualne różnice pod względem zmiennej zależnej (losowe intercepty/ ang. random intercepts)**
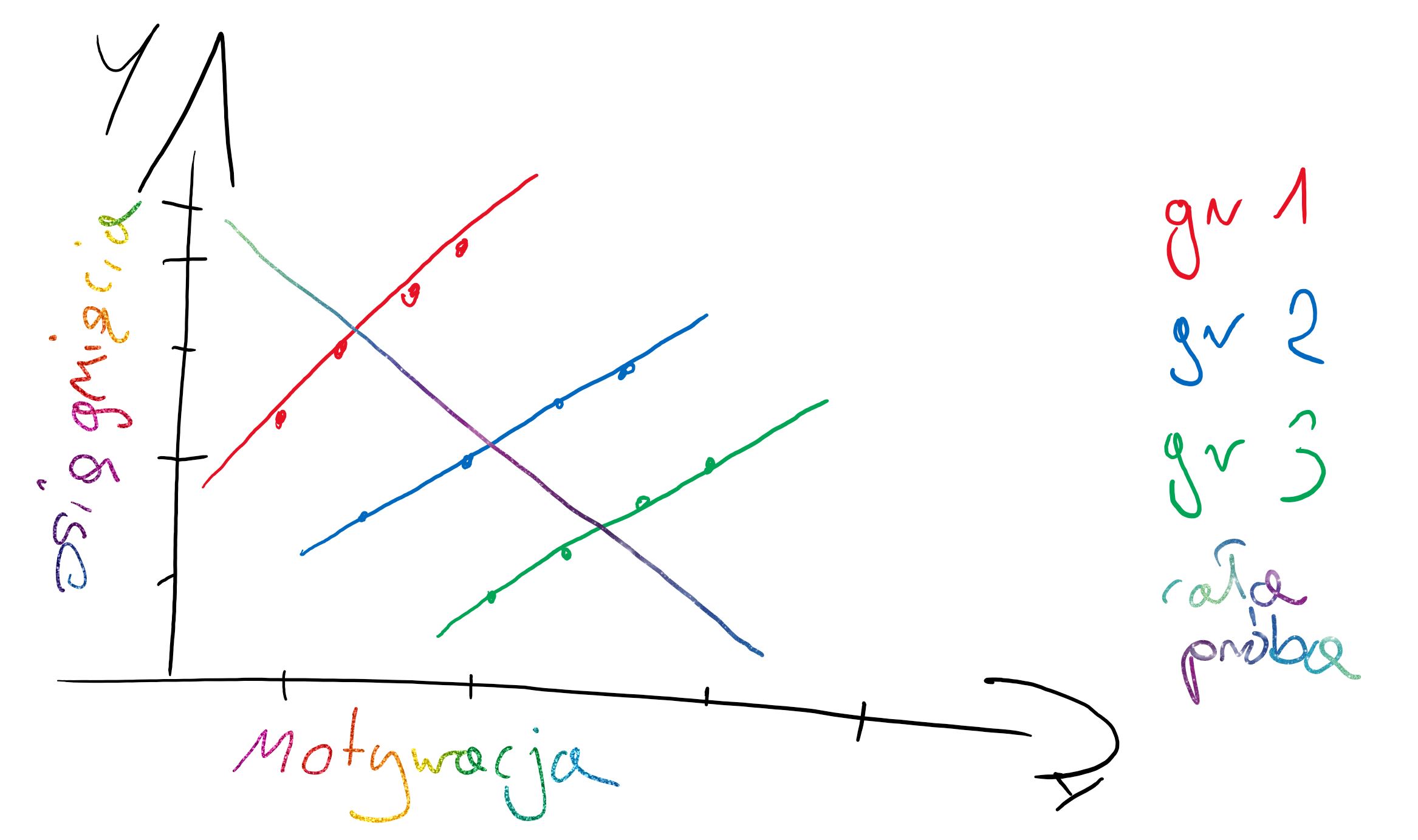
Każda grupa/obserwacja ma swoje oszacowanie średniego poziomu mierzonej cechy.
Model ten nazywa się modelem zerowym w którym obserwuje się czy są losowe różnice miedzy grupami/obserwacjami.
**Losowe różnice pod względem zmiennej zależnej (losowe intercepty/ ang. random intercepts), ale stale linie regresji (ang. fixed slopes)**
Każda grupa/obserwacja ma swoje oszacowanie średniego poziomu mierzonej cechy, ale wpływ zmiennej niezależnej na badane zjawisko jest podobny we wszystkich grupach/obserwacjach.
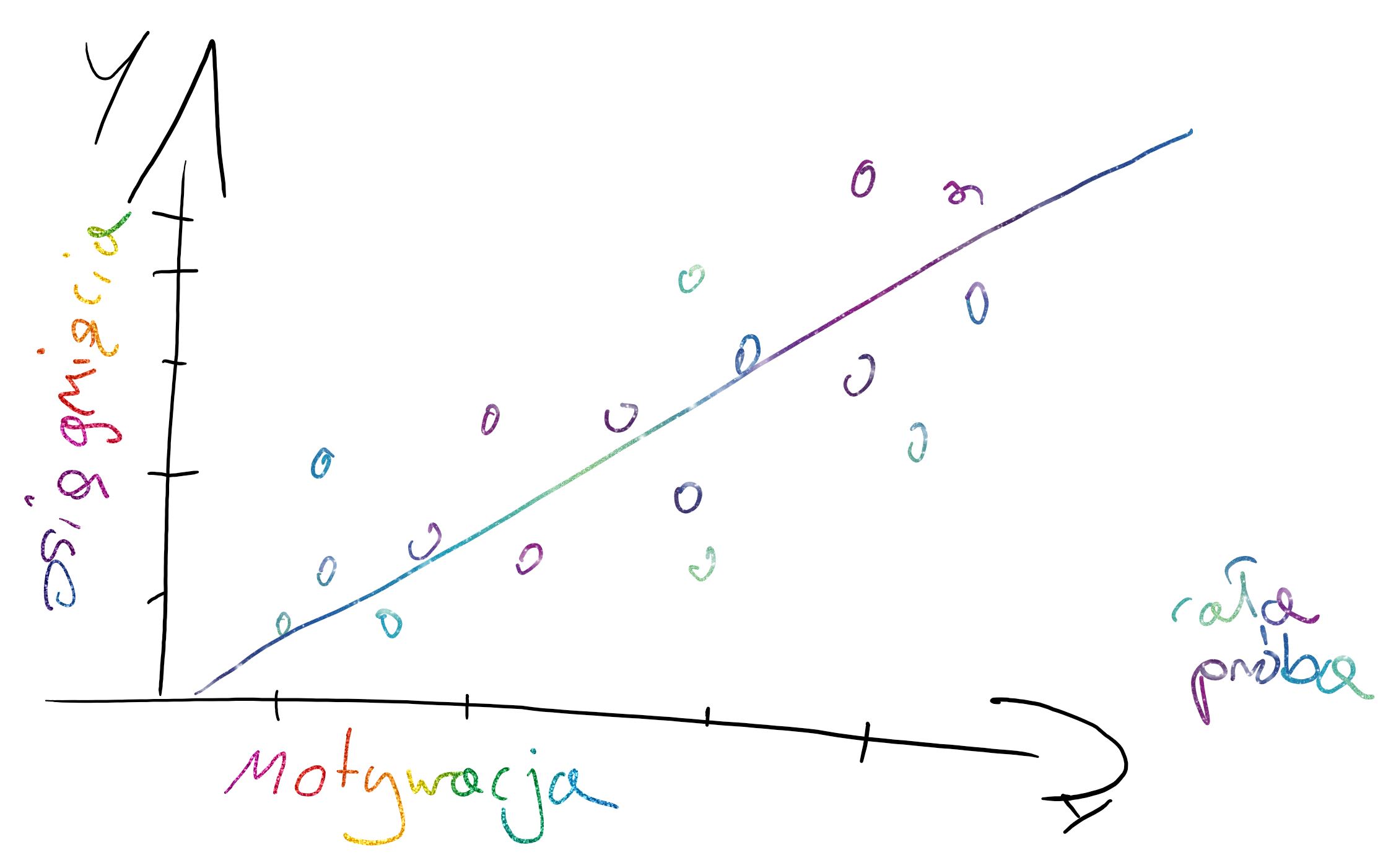
**Brak losowych różnic względem zmiennej zależnej (stale intercepty/ ang. fixed intercepts) oraz zachodzące różnice pod względem nachylenia linii regresji (ang. random slopes)**
Każda grupa/obserwacja ma to samo oszacowanie średniego poziomu mierzonej cechy, ale wpływ zmiennej niezależnej na badane zjawisko jest losowo inny we wszystkich grupach/obserwacjach.
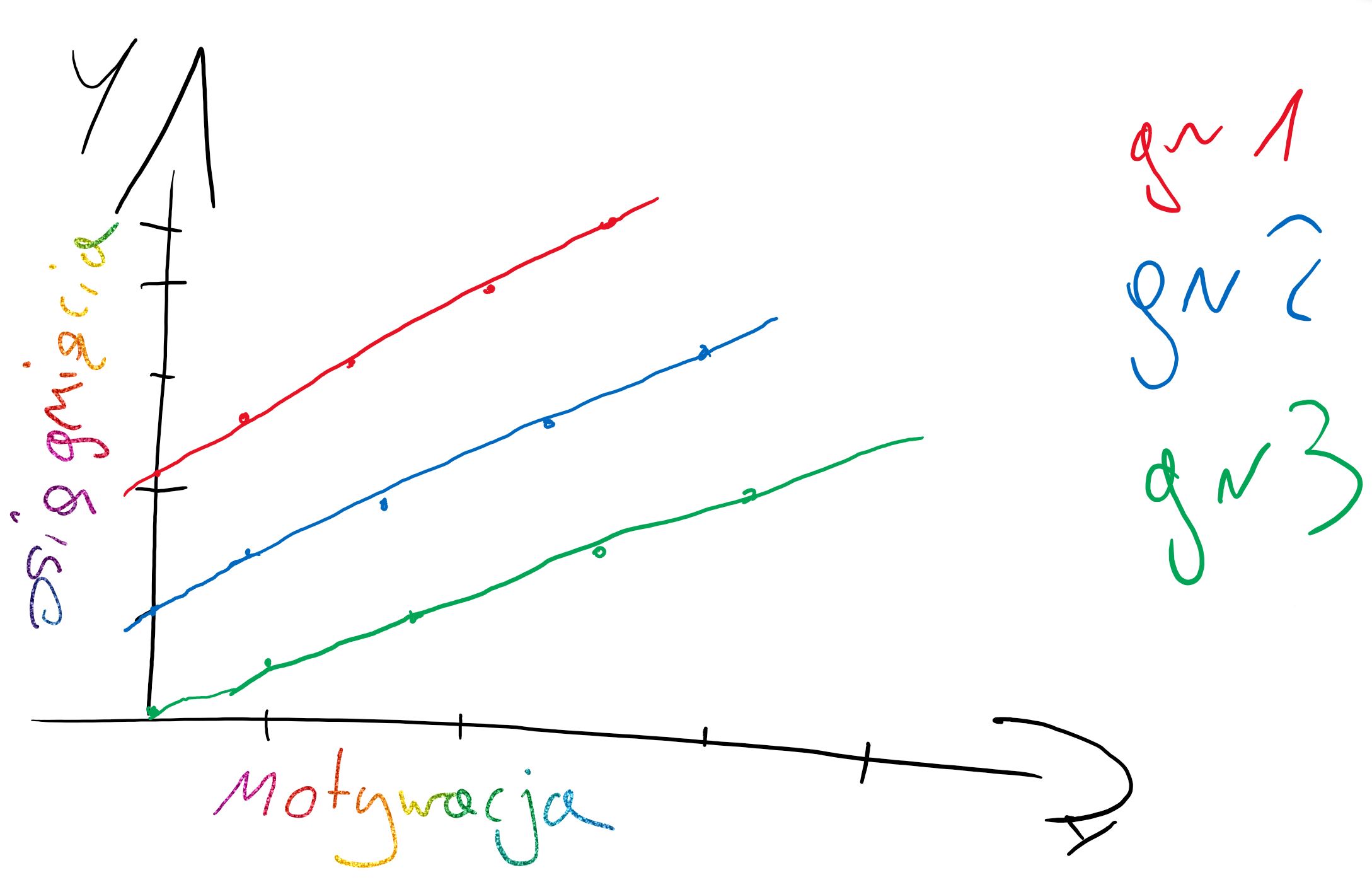
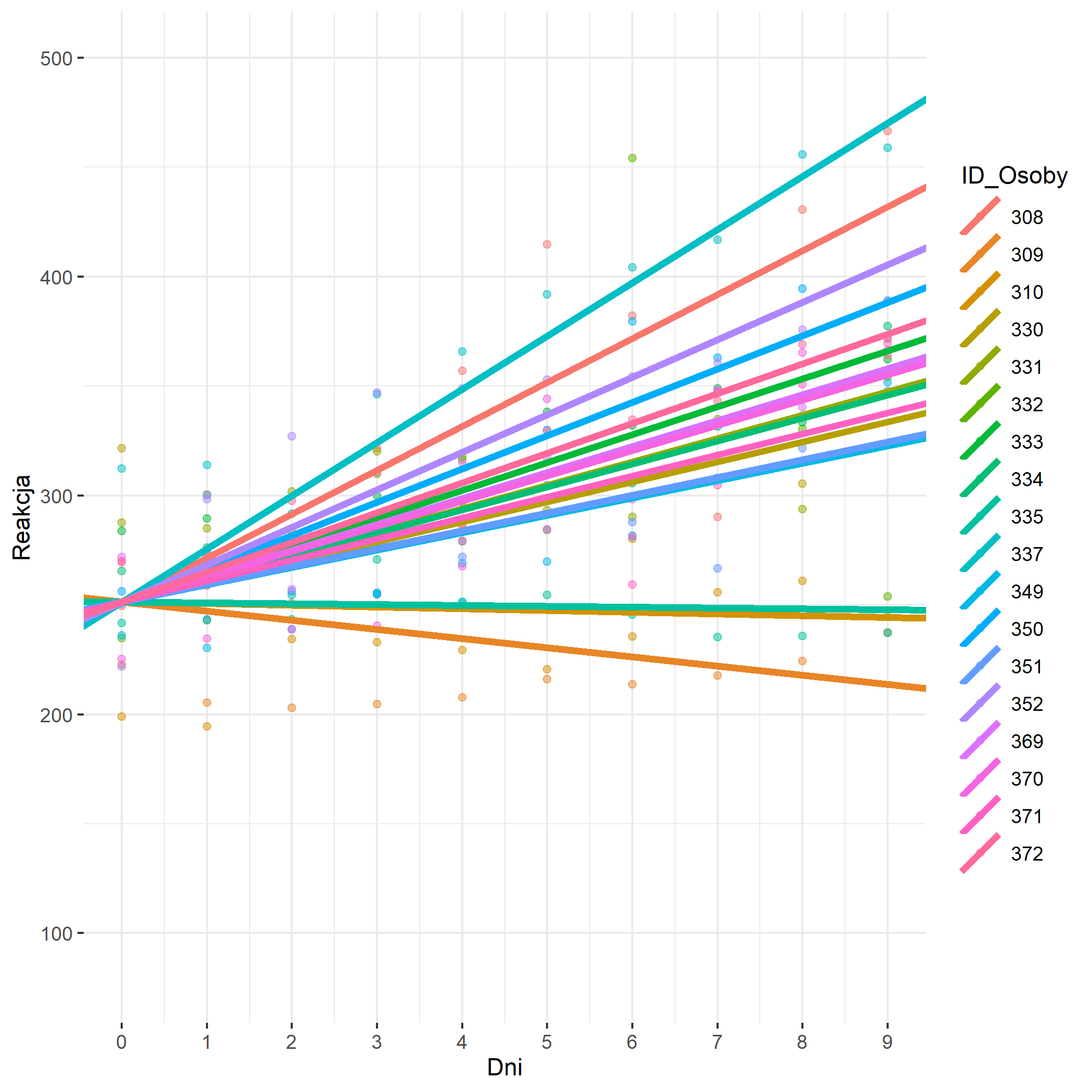
**Losowe różnice względem zmiennej zależnej (losowe intercepty/ ang. random intercepts) oraz różnice pod względem nachylenia linii regresji (ang. random slopes)**
Każda grupa/obserwacja ma rożne oszacowania średniego poziomu mierzonej cechy, ale wpływ zmiennej niezależnej na badane zjawisko jest losowo inny we wszystkich grupach/obserwacjach.
## **Dlaczego efekty mieszane?** ##
Dlatego, że można mieszać w tych modelach elementy random (intercepts i slopes) i fixed (również intercepts i slopes).
## **Opis zbioru danych na jakim będziemy ćwiczyć** ##
Baza danych zawiera informacje o tym jak deprywacja snu przez 10 dni wpływa u różnych ludzi na poziom szybkości reagowania na bodziec wizualny. Domniemuje się, ze im szybszy czas reakcji tym szybciej zachodzą procesy psychiczne w mózgu.
Układ jest bardzo prosty. Poszczególne pomiary dzienne czasu reakcji są zagnieżdżone w osobach. Dzień jest zmienną 1 poziomu (niższy poziom), a osoba jest zmienną 2 poziomu (wyższy poziom). Czas reakcji na bodziec to wartości zmiennej zależnej (wyjaśnianej) powtarzane przez 10 dni u wszystkich osób. Im wyższy czas reakcji, tym wolniejszy czas reakcji na bodziec co jest równoważnie z wolniejszym funkcjonowaniem mózgu i procesów umysłowych.
Na razie nie mamy zmiennych które bardziej określają poziom 1 i 2 analizy. Przez co, nie możemy wykonać interakcji między poziomami, ale do tego typu oszacowań przejdziemy pod koniec. Na razie zaczniemy od podstawowych kwestii związanych z modelowaniem efektów stałych, losowych i mieszanych, a także podstawowa terminologia i statystykami tych modeli.
Podsumowując:
Reakcja = czas reakcji na bodziec (zmienna zależna)
Dni = dzień pomiaru (poziom 1)
Id_Osoby = Id poszczególnych badanych (poziom 2)
*Jak rozpoznać hierarchie w danych?*
– cechy niższego poziomu nie mogą wpływać na cechy wyższego poziomu (uczniowie na nauczyciela lub dzień pomiaru na zachowanie człowieka)
– mamy do czynienia z powtarzanym pomiarem tego samego obiektu (układ wewnątrzobiektowy)
## **Jak wygląda zbiór danych do modelowania wielopoziomowego?** ##
„`{r}
print.data.frame(mydata) #funkcja print.data.frame() pokazuje w konsoli R zbiór danych
„`
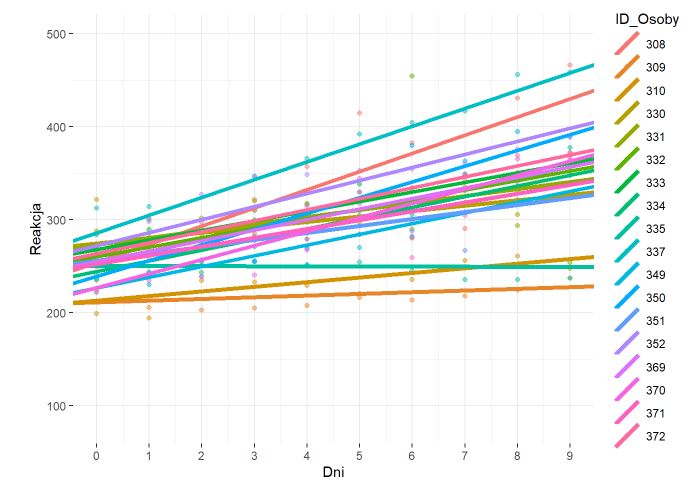
## **Model regresji liniowej jedna stała (fixed intercept) i jeden slope (fixed slope)** ##
„`{r}
reg_linear = lm(Reakcja ~ Dni , data = mydata) #Zwykla analiza regresji. Predyktorem jest czas liczony w dniach, a zależną jest szybkość wykonania zadania
jtools::summ(reg_linear) #Podsumowanie modelu regresji
„`
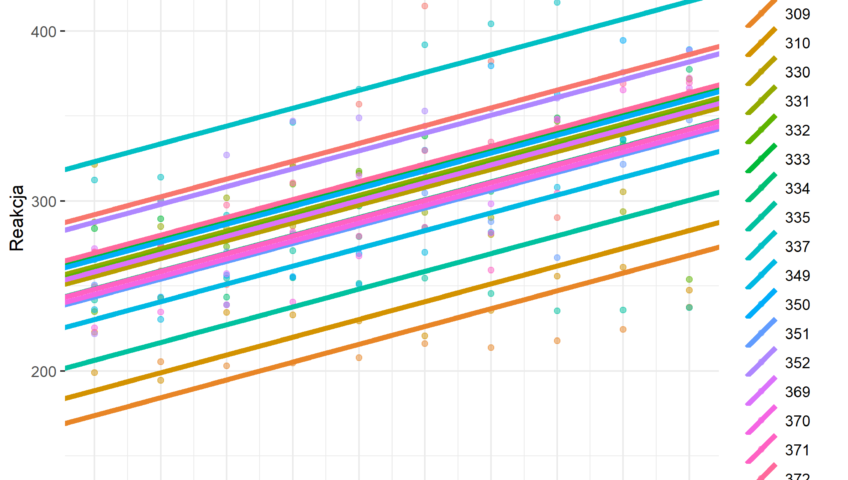
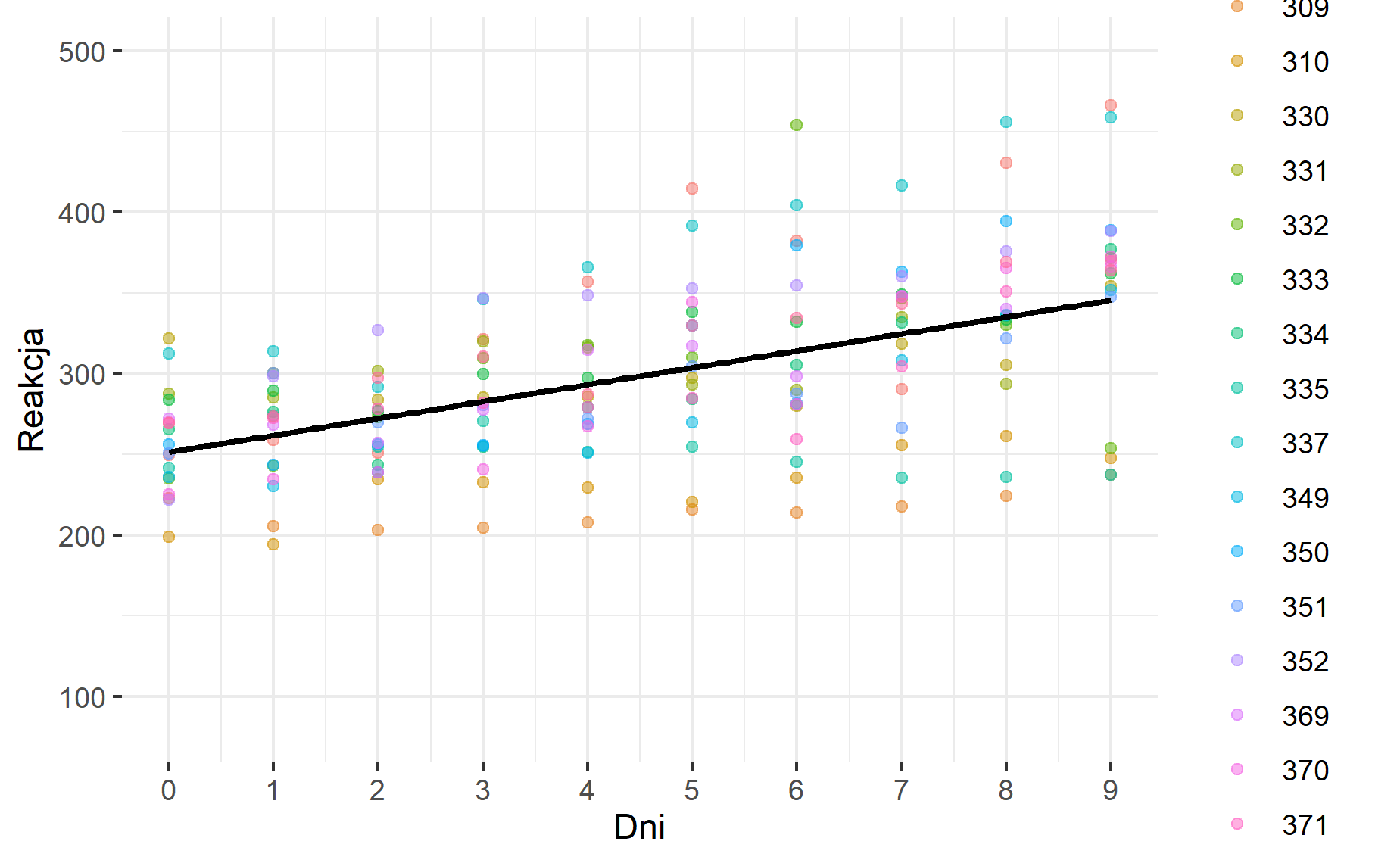
**Rysunek nr 1**
*Wizualizacja zwyklej regresji liniowej z jednym predyktorem (fixed intercept) i jeden slope (fixed slope)*
„`{r}
ggplot(data = mydata, mapping = aes(x = Dni, y = Reakcja)) + #definiowanie zbioru danych i zmiennych na wykrescie
geom_point(na.rm = T, aes(col = ID_Osoby), alpha = 0.5) + #pokazanie kolorowych punktów na wykresie rozrzutu względem zmiennej ID_osoby
geom_smooth(method = „lm”, na.rm = T, col = „black”, se = F) + #wykorzystanie funkcji liniowej do wykreślenia linii dopasowania
scale_y_continuous(limits = c(80, 500)) + #skalowanie osi y
scale_x_continuous(breaks = seq(1:10) – 1) + # skalowanie osi x
theme(legend.position = „right”)+theme_bw() + theme(panel.border = element_blank()) #ustawienia szablonu wykresu, pozycji legendy i tła
wykres1 = ggplot(data = mydata, mapping = aes(x = Dni, y = Reakcja)) + #definiowanie zbioru danych i zmiennych na wykrescie
geom_point(na.rm = T, aes(col = ID_Osoby), alpha = 0.5) + #pokazanie kolorowych punktów na wykresie rozrzutu względem zmiennej ID_osoby
geom_smooth(method = „lm”, na.rm = T, col = „black”, se = F) + #wykorzystanie funkcji liniowej do wykreślenia linii dopasowania
scale_y_continuous(limits = c(80, 500)) + #skalowanie osi y
scale_x_continuous(breaks = seq(1:10) – 1) + # skalowanie osi x
theme(legend.position = „right”)+theme_bw() + theme(panel.border = element_blank()) #ustawienia szablonu wykresu, pozycji legendy i tła
model0 = jtools::summ(M00) # Podsumowanie modelu zerowego (bez predyktorow), czyli weryfikacja tego czy nasze osoby różnią się ogólnie pod względem cechy reagowania na bodziec
# Model nie zawiera predyktora, czyli póki co źródłem zróżnicowania pomiarów reagowania jest sam człowiek, czyli jakieś źródło wariancji które identyfikujemy w tym modelu.
# (1 | ID_Osoby) = oznacza, ze intercepty dla poszczególnych ludzi są losowe (czyli, ze ludzie po prostu różnią się pod względem czasu reakcji)
model0
ggplot2::ggsave(wykres_model_zero , filename = „wykres_model_zero .png”, device = „png”, limitsize = F) #eksport wykresu
„`
## **Model regresji wielopoziomowej wiele stałych (random intercepts) i jeden slope (fixed slope)** ##
„`{r}
intercepts_model <- lmer(Reakcja ~ Dni + (1 | ID_Osoby), data = mydata, REML = F)
# Regresja wielopoziomowa.
# Predyktorem jest czas liczony w dniach, a zależną jest szybkość wykonania zadania
# (1 | ID_Osoby) = oznacza, ze intercepty dla poszczególnych ludzi są losowe (czyli, ze ludzie po prostu różnią się pod względem czasu reakcji)
jtools::summ(intercepts_model) #Podsumowanie modelu regresji
M0_intercepty = lmerTest::ranova(intercepts_model) #testowanie istotności zróżnicowania małych średnich (interceptów)
M0_intercepty
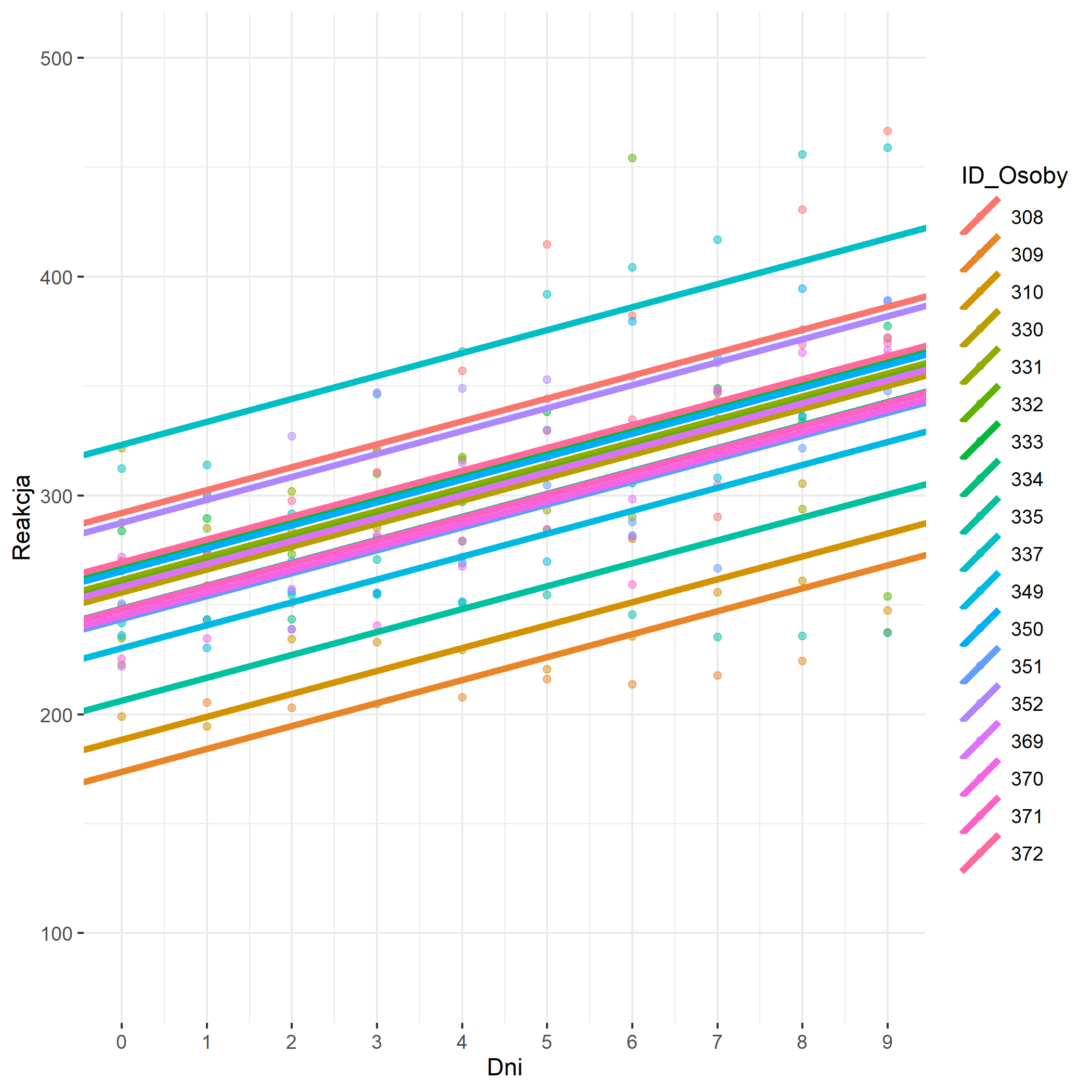
## **Model regresji wielopoziomowej jedna stałą (fixed intercept) i wieloma slopsami (random slopes)** ##
*Pozdrawiam i zapraszam do modelowania*
„`{r}
slopes_model <- lmer(Reakcja ~ Dni + (0+Dni | ID_Osoby), data = mydata, REML = F)
# Regresja wielopoziomowa
# Predyktorem jest czas liczony w dniach, a zależną jest szybkość wykonania zadania
# (0+Dni | ID_Osoby) = 0 oznacza, ze intercepty dla poszczególnych ludzi są stale (czyli, ze ludzie nie różnią się do siebie pod względem czasu reakcji, ale wpływ dni (zmienna niezależna) na reagowanie (zmienna zależna) jest różny u różnych ludzi)
jtools::summ(slopes_model) #Podsumowanie modelu regresji
M1_slopes = lmerTest::ranova(slopes_model) #testowanie istotności zróżnicowania slopsow u poszczególnych ludzi (pamiętajmy, że intercepty są przyjmują tę samą stałą wartość)
M1_slopes
## **Model regresji wielopoziomowej wiele stałych (random intercepts) i wiele slopsow (random slopes)** ##
„`{r}
intercepts_slopes_model <- lmer(Reakcja ~ Dni + (1+Dni | ID_Osoby), data = mydata, REML = F)
# Regresja wielopoziomowa
# Predyktorem jest czas liczony w dniach, a zależną jest szybkość wykonania zadania
# (1+Dni | ID_Osoby) = 1 oznacza, ze intercepty dla poszczególnych ludzi znów są losowe (czyli, ze ludzie różnią się od siebie pod względem czasu reakcji i tez tego jak upływ czasu wpływa na reagowanie)
jtools::summ(intercepts_slopes_model) #Podsumowanie modelu regresji
## **Porównywanie modeli pod względem dopasowania danych do rozpatrywanych modeli** ##
Niższy wynik AIC, BIC świadczy o lepszym dopasowaniu danych do modelu. Miary te nie maja wartości referencyjnych.
„`{r}
stats::anova(intercepts_slopes_model, slopes_model) #funkcja anova() pozwala na testowanie różnice miedzy modelami pod względem dopasowania danych do modelu
stats::anova(intercepts_slopes_model, intercepts_model)
stats::anova(slopes_model, intercepts_model)
„`
„`{r}
sjPlot::tab_model(M00, intercepts_model, slopes_model,intercepts_slopes_model, show.df = TRUE,show.aic = T, show.se = T ) #Funkcja tab_model() pakietu „sjPlot” elegancko zagnieżdża modele w jednej tabeli. Funkcja ta ma wiele innych fajnych ustawień.
„`
Szkolenie z analizy danych panelowych w programie R
Jakiś czas temu przeprowadzaliśmy na Uniwersytecie Ekonomicznym w Katowicach szkolenie z analizy danych panelowych, czyli analizy regresyjnej danych czasowo przestrzennych. Do tego szkolenia zostało przygotowane pełne zakodowanie analizy w programie R. Sama analiza regresji panelowej została wykonana za pośrednictwem pakietu „plm”. Poniżej jest zapisany cały kod pozwalający na analizę danych panelowych różnymi sposobami estymacji wyników analizy regresji panelowej.
Serwis korzysta z plików cookies. Dowiedz się więcej na temat Polityki cookies i możliwości zmiany ustawień cookies w Twojej przeglądarce. Korzystając z serwisu wyrażasz zgodę na używanie cookies, zgodnie z ustawieniami przeglądarki.