
Trafność różnicowa konstruktów – Podstawowe założenie w modelowaniu równań strukturalnych SEM CB i SEM PLS
Trafność różnicowa konstruktów, to po angielsku discriminant validity. Jest to moim zadaniem założenie podstawowe jeśli chodzi o ocenę trafności pomiarów i możliwości wnioskowania na temat relacji między zmiennymi w modelu strukturalnym. Dlaczego trafność różnicowa konstruktów jest taka ważna? Dlaczego powinno być pierwszym założeniem jakie weryfikujemy w toku budowy modelu strukturalnego (Iacobucci, 2010; Kock, 2020; Pearl, 2009; Tarka, 2017)? Kiedy mamy pewność, że relacja między zmiennymi wynika z badanego efektu, a kiedy jest to efekt podobieństwa konstruktów do siebie? Jak konceptualizować i budować skale pomiarowe, by charakteryzowały się one trafnością dyskryminacyjną? Zachęcam do czytania.

Dlaczego analiza trafności różnicowej konstruktów jest taka ważna i kiedy wyciągamy poprawne wnioski na temat relacji w utworzonym modelu strukturalnym?
Podstawą do wyciągania wniosków na temat testowanych relacji w modelu strukturalnym jest utworzenie modelu pomiarowego zmiennych który jest dopasowany do zebranych danych. Jeśli zmienne które mierzymy w modelu są trafne różnicowo, są rzetelne, trafne czynnikowo i cechują się niską współliniowością (a także innymi założeniami jak np. Paradox Simpsona i Statystyczna Supresja (Kock, 2020; Kock & Gaskins, 2016)), to możemy przejść do wyciągania pewnych wniosków na temat relacji między badanymi zmiennymi (Hair et al., 2019; Kock, 2014; Ringle et al., 2020; Van Riel et al., 2017). Niemniej, trafność różnicowa i jej analiza…
Analiza trafności różnicowej konstruktów odnosi się do zjawiska polegającego na tym, że zmienne obserwowalne tworzące czynnik A (np. pytania w kwestionariuszu A) mierzą inny aspekt rzeczywistości niż zmienne obserwowalne tworzące czynnik B (pytania w kwestionariuszu B). Jeśli zmienne obserwowalne z czynnika A i B mierzą podobny aspekt rzeczywistości, to znaczy, że relacja między zmiennymi A i B wynika z tego, że mierzą one podobny aspekt rzeczywistości, a nie z działania efektu który poddajemy badaniu. Wymaganie stawiane przez założenie o trafności różnicowej pomiarów stawia badacza w sytuacji w której musi zastanowić się on nad wykonaniem pomiarów w taki sposób, by dokładnie mierzyć aspekty rzeczywistości które są trudno odróżnialne. Np. neurotyczność i neurotyzm mogą mieć podobne znaczenie, a do tego brzmią jak synonimy. Niemniej, mogą mieć one całkowicie inne znaczenie teoretyczne np. neurotyczność może odnosić się do emocjonalnego reagowania, a neurotyzm do emocjonalnego stylu przetwarzania informacji. Jeśli badacz nie zadba o dokładny pomiar jednego i drugiego elementu (nie ułoży pytań które odróżniają te dwa neuroaspekty, to musi się liczyć z tym, że jego metoda badania nie będzie realizowała ustalonych celów badawczych np. co ma większy wpłw na depresje neuro-reagowanie czy neuro-myślenie. Trafność różnicowa pomiarów w statystyce…
W tym miejscu wyłania się pytanie: Jak odróżniać od siebie rzeczy, które są do siebie bardzo podobne i jak budować skale pomiarowe, by charakteryzowały się one pożądaną trafnością dyskryminacyjną?
Myślę, że im lepsze przygotowanie teoretyczne badacza tym lepiej. Im więcej człowiek wie na temat badanej rzeczywistości, tym łatwiej mu odróżniać od siebie poszczególne jego elementy. Badacze, a w szczególności badacze zajmujący się badaniami psychologicznymi, muszą dobrze wiedzieć co badają. Najlepiej sprawdza się tutaj posiadanie dobrych definicji operacyjnych których korzenie są mocno zapuszczone w teorii lub tradycji badań danego przedmiotu.
Jakiś czas temu osobiście stałem przed zadaniem pomiaru dwóch podobnych do siebie konstruktów Postrzeganej Łatwości Użytkowania Technologii i Postrzeganej Użyteczności Technologii zaczerpniętej z teorii Technologii Akceptacji Technologii (Davis, Fred D.Bagozzi, Richard P.Warshaw, 1989; Davis, 1989). W teorii tej testuje się zmienne które wiążą się z chęcią skorzystania z technologii lub/i aktualne korzystanie z jakiejś technologii np. w moim badaniu była to chęć korzystania z technologii samochodu autonomicznego. Jak uzyskać zpełnione założenie jakim jest trafność różnicowa konstruktów? Czym ze strony teoretycznej przygotować się do oceny zjawiska jakim jest analiza trafności dyskryminacyjnej?
Davis (1989) na podstawie teorii odróżnił i zoperacjonalizował swoje konstrukty wchodzące w skład Modelu Akceptacji Technologii (Technology Acceptance Model). Zdefiniował łatwość użycia technologii jako osobiste przekonanie, że użycie technologii jest bezwysiłkowe, a postrzegana użyteczność jest przekonaniem, że technologia polepszy osobiste dążenia lub wykonanie pracy. W teorii, aspekty użyteczności i łatwości są względnie odróżnialne, ale w empirii może to nastręczać trochę kłopotów, ponieważ trzeba zmierzyć użyteczność i łatwość w taki sposób, by osoby badane odróżniały jedno od drugiego. Aczkolwiek, chwila zastanowienia się nad nimi doprowadzi nas do wniosku, że pomimo tego, że coś może być użyteczne, to może być trudne w obsłudze (język programowania PYTHON). A może być też tak, że coś może być łatwe w obsłudze, ale bezużyteczne (różdżka radiestety). Przy tworzeniu pozycji testowych mających na celu pomiar tych konstruktów warto mieć z tyłu głowy teoretycznie zróżnicowanie ich znaczenia. Jedynie łącząc teorię z metodą możemy uzyskać trafność różnicową testowanych konstruktów. Trafność różnicowa konstruktów w statystyce.
Ja w swoim badaniu dotyczącym akceptacji technologii autonomicznych aut stworzyłem po 4 pozycje testowe na oba konstrukty teoretyczne. Warto zwrócić uwagę na to jak one brzmią i jak łatwo można wskazać różnice między pozycjami testowymi danego czynnika pod względem tego, co one mierzą. Dzięki takiej zróżnicowanej treści pozycji testowych osoby badane wyraźnie inaczej reagują (nie mylą ich ze sobą) na pozycje testowe związane z pomiarem postrzeganej łatwości i użyteczności. Dzięki temu, na poziomie analizy wynikiem oczekiwanym jest spełnione założenie o trafności różnicowej (Fornell & Larcker, 1981; Henseler et al., 2014).
Pomiar Postrzeganej Łatwości Użytkowania Technologii:
- Używanie autonomicznego samochodu CRUISE nie wymaga dużo wysiłku.
- Jeżdżenie i poruszanie się autonomicznymi samochodami CRUISE jest łatwe.
- Pojazdy autonomiczne CRUISE są proste w obsłudze i każdy je zrozumie.
- Nie ma nic trudnego w poruszaniu się autami CRUISE.
Pomiar Postrzeganej Użyteczności Technologii:
- Samochód autonomiczny CRUISE, to bardzo użyteczna rzecz.
- Samojeżdżące samochody CRUISE mogą zrobić wiele dobrego.
- Autonomiczny samochód CRUISE stanie się symbolem pożyteczności.
- Przydatność samochodów autonomicznych CRUISE będzie powszechna.
Warto mieć na uwadze, że większość recenzentów w dobrych journalach naukowych kładzie nacisk na weryfikacje założenia o trafności różnicowej/trafności dyskryminacyjnej. Wynika to z prostego zjawiska jakim jest commond method bias (Kock, 2015; Podsakoff et al., 2003) i które bardzo często występuje w przypadku kiedy źródłem informacji na różne tematy jest ta sama obserwacja, czyli np. człowiek.
Poniższa tabela przedstawia dwie metody oceny trafności różnicowej konstruktów wykorzystanej podczas analizy modeli równań strukturalnych metodą Multi Group Analysis (MGA) w artykule Hryniewicz & Grzegorczyk (2020).
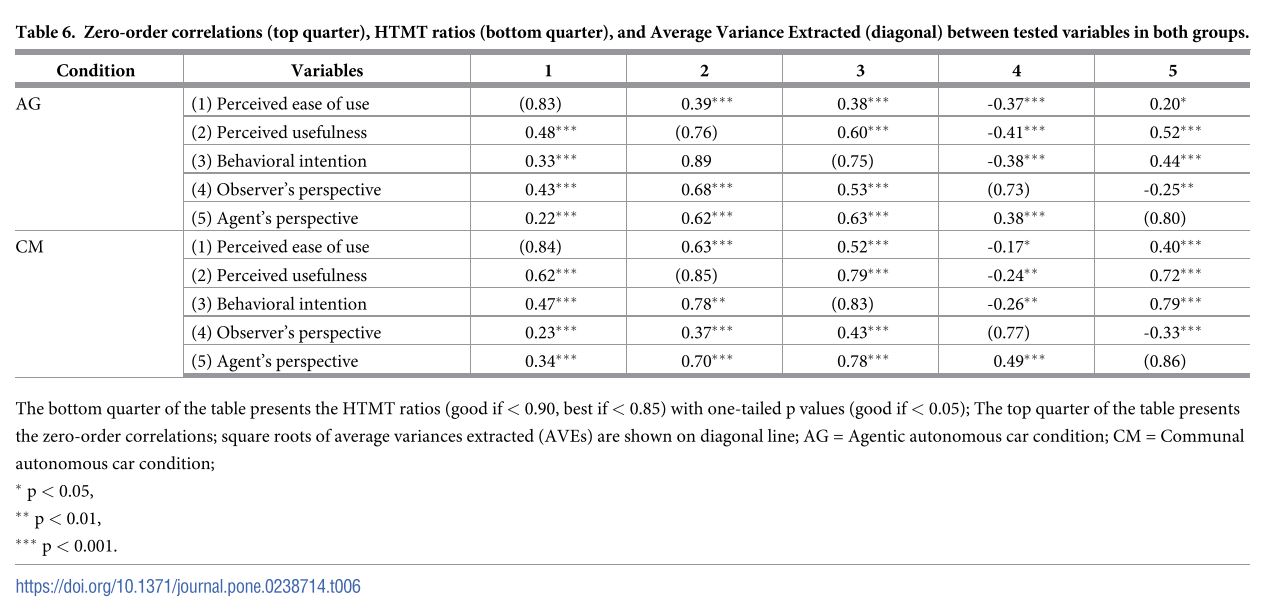
WAŻNE – Analiza trafności różnicowej/dyskrymiancyjnej
Przypomnę, że jeśli nasze konstrukty są trafne różnicowo, to wiemy, że ewentualna zależność między nimi zależy od badanego efektu np. właściwości technologii. Konstrukty nietrafne, czyli takie które wprowadzają tę samą informację o badanym przedmiocie, uniemożliwiają trafne wnioskowanie na temat relacji, ponieważ relacja między zmiennymi zależdy bardziej od podobnej metody pomiaru niż efektu poddawanego badaniu. Konstrukty trafne przybliżają nas do ukazania prawdy naukowej. Konstrukty nietrafne różnicowo lub ignorowanie tych zjawisk oddala nas od poznania prawdy naukowej i możliwości publikacji wysokiej jakości pracy. Dlatego trafność różnicowa konstruktów jest tak ważnym według mnie założeniem w badaniach i statystyce. Trafność różcnicowa w SEM!

Bibliografia:
Davis, Fred D.Bagozzi, Richard P.Warshaw, P. R. (1989). User Acceptance of Computer Technology: a Comparison of Two Theoretical Models. Management Science, 35(8), 982–1003. https://doi.org/http://dx.doi.org/10.1287/mnsc.35.8.982
Davis, F. D. (1989). Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. MIS Quarterly, 13(3), 319–340. https://doi.org/10.2307/249008
Fornell, C., & Larcker, D. F. (1981). Evaluating Structural Equation Models with Unobservable Variables and Measurement Error. Journal of Marketing Research, 18(1), 39. https://doi.org/10.2307/3151312
Hair, J. F., Ringle, C. M., Gudergan, S. P., Fischer, A., Nitzl, C., & Menictas, C. (2019). Partial least squares structural equation modeling-based discrete choice modeling: an illustration in modeling retailer choice. Business Research, 12(1), 115–142. https://doi.org/10.1007/s40685-018-0072-4
Henseler, J., Ringle, C. M., & Sarstedt, M. (2014). A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science, 43(1), 115–135. https://doi.org/10.1007/s11747-014-0403-8
Hryniewicz, K., & Grzegorczyk, T. (2020). How different autonomous vehicle presentation influences its acceptance: Is a communal car better than agentic one ? PLoS ONE, 1–28. https://doi.org/10.1371/journal.pone.0238714
Iacobucci, D. (2010). Structural equations modeling: Fit Indices, sample size, and advanced topics. Journal of Consumer Psychology, 20(1), 90–98. https://doi.org/10.1016/j.jcps.2009.09.003
Kock, N. (2014). A note on how to conduct a factor-based PLS-SEM analysis A note on how to conduct a factor-based PLS-SEM analysis. International Journal of E-Collaboration, 11(3), 1–9. https://doi.org/10.4018/ijec.2015070101
Kock, N. (2015). Common method bias in PLS-SEM : A full collinearity assessment approach. 1–10.
Kock, N. (2020). WarpPLS User Manual: Version 7.0 (7th ed.). ScriptWarp Systems.
Kock, N., & Gaskins, L. (2016). Simpson’s paradox, moderation, and the emergence of quadratic relationships in path models: An information systems illustration. International Journal of Applied Nonlinear Science, 2(3), 200–234. https://doi.org/10.1109/ICUMT.2009.5345351
Pearl, J. (2009). Causality: Models, Reasoning and Inference (2nd ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511803161
Podsakoff, P. M., MacKenzie, S. B., Lee, J.-Y., & Podsakoff, N. P. (2003). Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology, 88(5), 879–903. https://doi.org/10.1037/0021-9010.88.5.879
Ringle, C. M., Sarstedt, M., Mitchell, R., & Gudergan, S. P. (2020). Partial least squares structural equation modeling in HRM research. International Journal of Human Resource Management, 31(12), 1617–1643. https://doi.org/10.1080/09585192.2017.1416655
Tarka, P. (2017). An overview of structural equation modeling: its beginnings, historical development, usefulness and controversies in the social sciences. Quality and Quantity, 52(1), 313–354. https://doi.org/10.1007/s11135-017-0469-8
Van Riel, A. C. R., Henseler, J., Kemény, I., & Sasovova, Z. (2017). Estimating hierarchical constructs using consistent partial least squares: The case of second-order composites of common factors. Industrial Management and Data Systems, 117(3), 459–477. https://doi.org/10.1108/IMDS-07-2016-0286