
Analiza modelowania równań strukturalnych w pakiecie lavaan
Modelowanie równań strukturalnych (SEM, Structural Equation Modeling) to zaawansowana technika statystyczna wykorzystywana do badania złożonych relacji między zmiennymi. SEM łączy w sobie elementy analizy czynnikowej, analizy ścieżkowej i regresji, umożliwiając jednoczesne uwzględnienie wielu zmiennych oraz uwzględnienie błędów pomiaru. Jest szeroko stosowane w naukach społecznych, psychologii, ekonomii, epidemiologii, marketingu i innych dziedzinach.
Główne komponenty modelowania równań strukturalnych to:
- Model czynnikowy (CFA, Confirmatory Factor Analysis): Pozwala on na badanie struktury czynnikowej, tj. identyfikowanie ukrytych (nieobserwowalnych) zmiennych, zwanych czynnikami, które wpływają na obserwowalne zmienne.
- Analiza ścieżkowa: SEM pozwala modelować związki kierunkowe między zmiennymi (tzw. ścieżki) i oceniać siłę tych związków. Możliwe jest uwzględnienie zarówno zmiennych niezależnych, jak i zmiennych zależnych.
- Model strukturalny: To główna część SEM, która opisuje teoretyczne relacje między zmiennymi. Model ten obejmuje zarówno czynniki, jak i związki między nimi.
- Błędy pomiaru: SEM pozwala uwzględniać błędy pomiaru, co jest istotne w przypadku, gdy zmienne są mierzone z pewnym stopniem niedokładności.
- Modelowanie wariancji i kowariancji: SEM pozwala na modelowanie struktury wariancji i kowariancji między zmiennymi, co umożliwia lepsze zrozumienie wzajemnych relacji.
SEM jest użyteczne w badaniach, gdzie istnieje potrzeba zrozumienia złożonych struktur relacji między zmiennymi. Przykłady zastosowań obejmują badania nad wpływem czynników psychologicznych na zdrowie, analizę skomplikowanych modeli marketingowych, czy badania nad edukacją. W praktyce wymaga zaawansowanej wiedzy statystycznej i programowania, ale dostępne są również narzędzia komputerowe ułatwiające stosowanie SEM.
Czym jest pakiet lavaan w systemie R?
Modelowanie równań strukturalnych w pakiecie lavaan jest super, a sam lavaan niesamowicie rozpowszechnionym pakietem do analizy modeli zmiennych latentnych. Skrót lavaan odnosi się właśnie do terminu „latent variables analysis” i jest pakietem bibliotek statystycznych do analizy modelowania równań strukturalnych i modeli czynnikowych w oparciu o badanie zbieżności między teoretyczną macierzą wariancji-kowariancji a tą samą macierzą wynikającą z zebranych danych. Ta metoda modelowania, pomimo swoich superlatyw ma też swoje ograniczenia i wady. Statystyczne i teoretyczne, ale o nich można przeczytaj obszetniej tutaj -> (Tarka, 2017). Poza tym analiza modelowania równań strukturalnych w pakiecie lavaan, a także w innych programach (Lisrel, Amos, Mplus) stoi w opozycji do modelowania metodą cząstkowych najmniejszych kwadratów (partial least squares [PLS]) zorientowanią predykcyjnie, a nie konfirmacyjnie (Garson, 2016; Vinzi et al., 2010). Metoda PLS też doczekała się swojej implementacji w R w pakiecie ‘plspm’ (Sanchez, 2013) lub SEMinR (Ray, Danks, and Valdez (2021). To też jest bardzo fajny pakiet zawierający dużo sposobów wizualizacji danych, szczególnie wyników modelu pomiarowego i strukturalnego.

Możliwości statystycznego analizowania danych w pakiecie lavaan
Niemniej, wracając do analizy modelowania równań strukturalnych w pakiecie lavaan, to pakiet ten daje nam niesamowite możliwości analizy modeli teoretycznych w różnych układach metodologicznych, a także za pomocą różnych form estymacji wyników. Dzięki specyficznemu syntaksowi w pakiecie lavaan możemy wykonać analizy dotyczące:
- Analizy konfirmacyjnych modeli czynnikowych
- Analizy modeli strukturalnych
- Analizy zmiennych kategorialnych
- Analizy wielogrupowe (testowanie modelu w różnych grupach badawczych)
- Analizy wzrostu zmiennej latentnej (np. wynikającej z czasu lub rozwoju). W tym przypadku możemy ustalić losowe intercepty (losowe efekty średnich) i losowe slopy (losowe nachylenia regresji)
- Analizy na podstawie samej macierzy wariancji kowariancji
- Analizy efektów mediacji
- Analizy indeksów modyfikacji (kalibracja dopasowania danych do modelu)
- Analizę wielopoziomowego modelowania równań strukturalnych w przypadku danych klastrowanych (pakiet lavaan pozwala na ustawienie efektów losowych interceptów, ale nie slopesów). Niemniej dane muszą być ciągłe, a także kompletne).
Najciekawsze w pakiecie lavaan są różne metody estymacji modeli, szczególnie tych odpornościowych np. MLMVS metoda największej wiarygodności z odpornymi błędami standardowymi, a także skorygowanymi średnimi i wariancjami ULSMV dla danych kategorialnych.
Pakiet lavaan jest dobrym rozwiązaniem dla początkujących
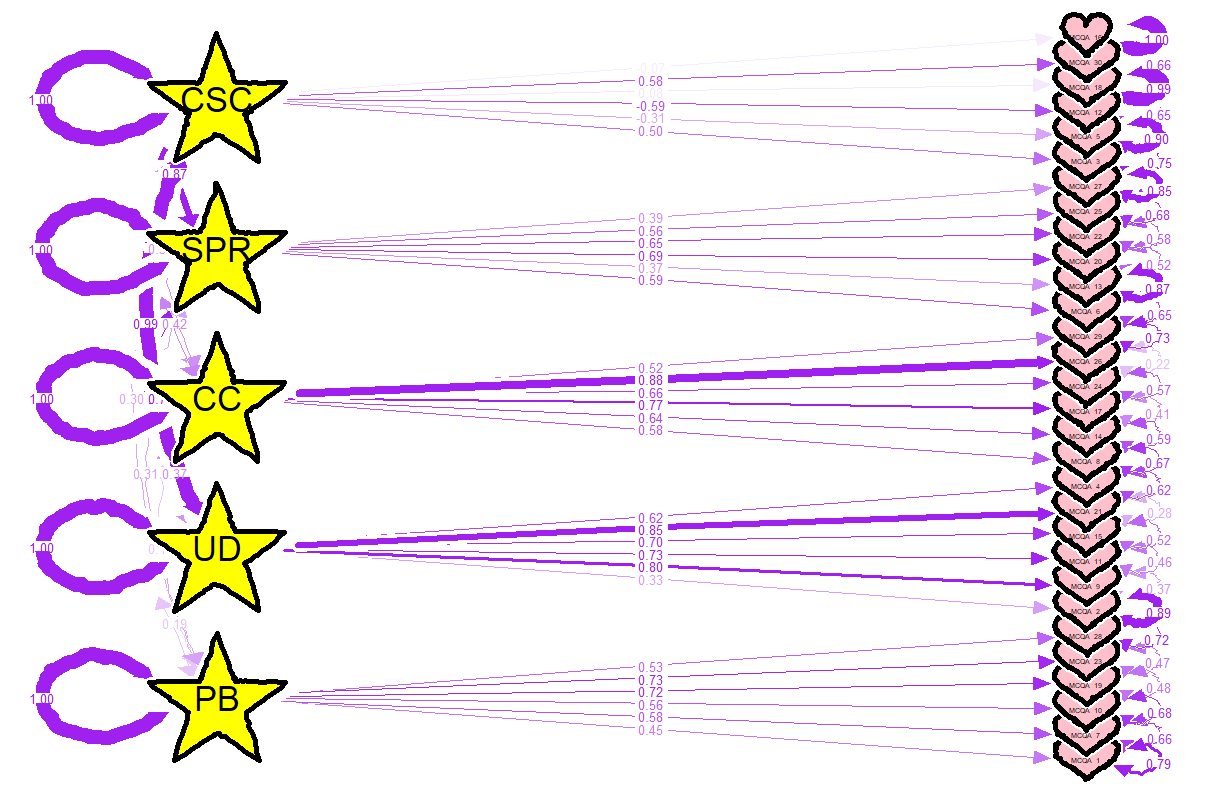
Pakiet lavaan jest o tyle lepszy od innych pakietów i bibliotek w R, że nie wymaga raczej eksperckiej wiedzy na temat R. Pakiet lavaan został zaprojektowany by był łatwy w użyciu dla osób, które nie używają eRa na co dzień. Można w nim już na samym początku zrobić taki wykres konfirmacyjnej analizy czynnikowej 🙂
Bibliografia
Garson, G. D. (2016). Partial Least Squares: Regression & Structural Equation Models. In G. David Garson and Statistical Associates Publishing. Statistical Associates Publishing.
Ray S, Danks N, Calero Valdez A (2022). _seminr: Building and Estimating Structural Equation Models_. R package version 2.3.2, <https://CRAN.R-project.org/package=seminr>.
Sanchez, G. (2013). PLS Path Modeling with R. R Package Notes, 235. https://doi.org/citeulike-article-id:13341888
Tarka, P. (2017). An overview of structural equation modeling: its beginnings, historical development, usefulness and controversies in the social sciences. Quality and Quantity, 52(1), 313–354. https://doi.org/10.1007/s11135-017-0469-8
Vinzi, V. E., Trinchera, L., & Amato, S. (2010). Handbook of Partial Least Squares (V. E. Vinzi, L. Trinchera, & S. Amato (eds.)). Springer. https://doi.org/https://doi.org/10.1007/978-3-540-32827-8