
Szkolenie z analizy danych panelowych w programie R
Jakiś czas temu przeprowadzaliśmy na Uniwersytecie Ekonomicznym w Katowicach szkolenie z analizy danych panelowych, czyli analizy regresyjnej danych czasowo przestrzennych. Do tego szkolenia zostało przygotowane pełne zakodowanie analizy w programie R. Sama analiza regresji panelowej została wykonana za pośrednictwem pakietu „plm”. Poniżej jest zapisany cały kod pozwalający na analizę danych panelowych różnymi sposobami estymacji wyników analizy regresji panelowej.
W tym miejscu są niezbędne pakiety, a także biblioteki, by wykonać wszystkie analizy, wykresy i procedury.
install.packages(„openxlsx”)
install.packages(„plm”)
install.packages(„gplots”)
install.packages(„tidyverse”)
install.packages(„readr”)
install.packages(„ggplot2”)
install.packages(„readxl”)
install.packages(„lmtest”)
library(plm) # Wgranie biblioteki do analizy panelowej
library(tidyverse) # Zarzadzanie danymi
library(readr) # Odczytywanie danych z csv
library(gplots) # Wizualizacja danych panelowych
library(ggplot2) # Wizualizacja zaleznosci miedzy zmiennymi w panelu
library(openxlsx) # Wczytanie tabeli w excelu
library(readxl) # Wczytanie tabeli w excelu
library(haven) # wczytanie tabeli w spss
library(lmtest) #wczytanie testow diagnostycznych heteroscedastycznosci i korekcji modelu
Import baz danych do srodowiska R w celu przygotowania danych do analizy danych panelowych i eksploracji danych pod kątem przeprowadzania analizy regresji panelowej.
# Ustalenie folderu roboczego w ktorym wczytujemy wszystkie dane i zapisujemy efekty prac
setwd(‚C:\\Users\\Użytkownik\\Desktop\\Szkolenie_Panel Data_in_R’)
# Ta funkcja pokazuje jaka jest aktualna sciezka do folderu roboczego
getwd()
# Zaciagniecie bazy danych w formacie csv gdzie wartosci oddzielane sa przecinkiem
naszedane = read.csv(‚C:\\Users\\Użytkownik\\Desktop\\Szkolenie_Panel Data_in_R\\panel_wage.csv’)
# Niemniej, tak skrotowo tez mozna zrobic to samo
naszedane = read.csv(‚panel_wage.csv’)
# Zaciagniecie bazdy danych w formacie XLSX
naszedanewXLSX = read_xlsx(‚C:\\Users\\Użytkownik\\Desktop\\Szkolenie_Panel Data_in_R\\Dan_ w_xlsx.xlsx’)
# Zaciagniecie bazy danych w formacie SAV (rozszerzenie SPSS)
# user_na = funkcja ktora pozwala na identyfikacje brakow danych, FALSE = oznacza ze nie ma zdefiniowanych brakow danych
naszedanewSPSS = read_sav(‚C:\\Users\\Użytkownik\\Desktop\\Szkolenie_Panel Data_in_R\\Dane_w_SPSS.sav’, user_na = FALSE)
# Tabela z wyjasnieniem metod estymacji modeli panelowych
analizaestymatorów = read.xlsx(‚Tabela_z_wariacjami.xlsx’)
#Funkcja class() sprawdza jakim typem obiektu jest dany obiekt w srodowisku R
class(naszedane)
class(naszedanewXLSX)
class(naszedanewSPSS)
class(TRUE)
class(„A”)
class(4)
Zmienne w naszej analizie regresji panelowej
# Y = Zmienna zależna to logarytm zarobków lwage
# X = Zmienne niezależne to: exp = dowiadczenie w firmie, exp2 = to doswiadczenie calkowite, wks = przepracowane cale tygodnie w roku,
# ed = Edukacja (zmienna niezależna od czasu)
#### Metody wizualizacji danych panelowych
# Sprawdzamy jakie sa roznice w zarobkach u poszczegolnych osob
plotmeans(lwage~id, main=”Zmiennosc Y w przekroju”, data = naszedane) #znak ~ zawsze oznacza modelowanie danej zmiennej
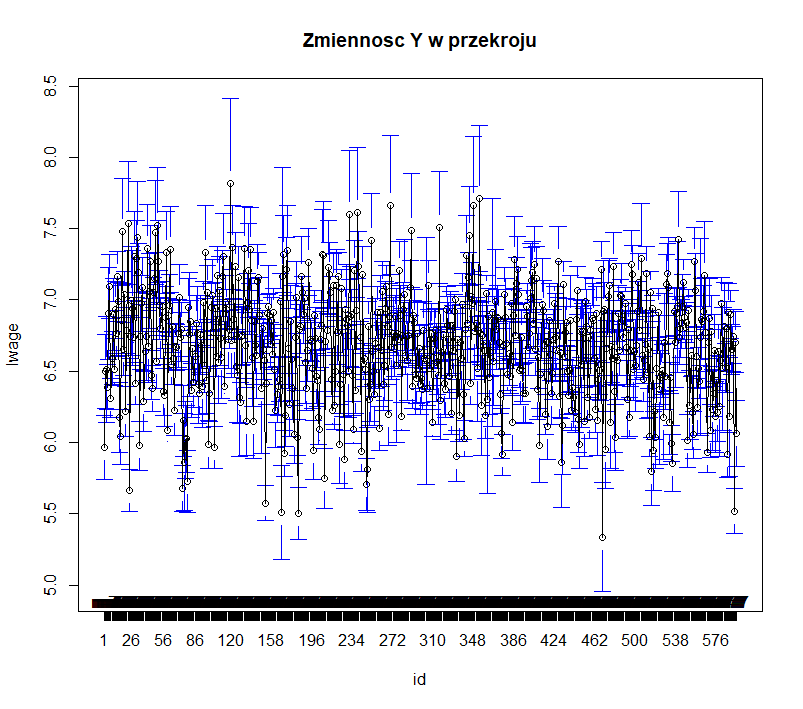
# Sprawdzamy jakie sa roznice w zarobkach w poszczegolnych latach
plotmeans(lwage~t, main=”Zmiennosc Y w czasie”, data = naszedane)

Szkolenie Analiza regresji i wizualizacja danych panelowych w R Metodolog.pl
Sposoby wizualizacji danych w pakiecie ggplot2
# Histogram zarobków
naszedane %>% ggplot(aes(x = lwage)) + #System wie, ze ma zaciagnac zmienna x jako lwage ze ramki naszedane
geom_bar() + # formowanie histogramu
scale_x_continuous(breaks = 1:8) # ustawienie przedzialek na skali x
# Histogram doswiadczenia
naszedane %>% ggplot(aes(x = exp)) +
geom_bar(fill = ‚red’) + #mozemy zmienic mu kolor
scale_x_continuous(breaks = 1:54)
# Histogram przepracowanych tygodni
naszedane %>% ggplot(aes(x = wks)) +
geom_bar(fill = ‚magenta’) +
scale_x_continuous(breaks = 10:54) #funkcja breaks ustawia przedzialki
# Histogram dla lat edukacji
naszedane %>% ggplot(aes(x = ed)) +
geom_bar() +
scale_x_continuous(expand = c(0, 0), breaks = seq(1, 17,3)) #a tutaj funckja breaks ustawia przedziale co dwa
# Histogram dla czasu (dla sprawdzenia czy panel jest zbalansowany)
naszedane %>% ggplot(aes(x = t)) +
geom_bar() +
scale_x_continuous()
# Jest, bo w kazdym czasie zmiennej t jest taka sama liczba obserwacji
# Panel niezbalansowany jest w przypadku brakow danych lub innych przyczyn nierownolicznosci np. decyzja o zakonczeniu badania
naszedane %>% ggplot(aes(y = lwage, x = exp)) + # Konstrukcja każdego wykresu
geom_point(color = „red”) # Wykres punktowy z czerwonymi kropkami. Kolory można zmieniac 🙂
naszedane %>% ggplot(aes(y = lwage, x = exp)) + # Konstrukcja każdego wykresu
geom_point(color = „magenta”) + # Wykres
geom_smooth() # Dodatki do wykresu np. wygladzona linia loess (lokalnie dopasowana)
Teraz zrobmy coś ciekawego. Poznajmy więcej informacji na temat naszej analizy panelowej
# Chcemy zobaczyc jak wygladaja zaleznosci miedzy exp a lwage w poszczegolnych latach
# Musimy zamienić zmienn numeryczna na zmienna typu factor, bo tylko tak mozemy umiescic informacje o czasie na wykresie
class(naszedane$t)
t2=as.factor(naszedane$t) # Funkcja zamieniajace status zmiennej t [integer] na t2 [factor]
class(t2) # Sprawdzamy czy faktycznie R zrobil to czego oczekiwalismy
# Zrobil 🙂
# Teraz mozemy uzyc zmiennej czasu by osadzic ja na wykresie pokazującej panel
naszedane %>% ggplot(aes(y = lwage, x = exp, color = t2)) + # konstrukcja każdego wykresu
geom_point(color = „black”) + # wykres
geom_smooth() #lokalnie dopasowana linia (Szkolenie Analiza Danych Panelowych w R Metodolog.pl)
# Mozemy dodac linie dopasowania jak np w analizie regresji
naszedane %>% ggplot(aes(y = lwage, x = exp)) + # Konstrukcja każdego wykresu
geom_point(color = „black”) + # Wykres
geom_smooth(method = „lm”) # Dodatki do wykresu i dodana lina regesji „lm”znaczy tyle co linear model
# Mozemy tez dodać linię dla zmienej czas argumentem color (wizualizacja wyników regresji panelowej).
# Polorujemy linie regresji
naszedane %>% ggplot(aes(y = lwage, x = exp,color = t2)) +
geom_point(color = „black”) + # Wykres
geom_smooth(method = „lm”)
# Możemy tez zobaczy jak wyglada funkcja kwadratowa
# Dodajemy funkcje kwadratowa
naszedane %>% ggplot(aes(y = lwage, x = exp,color = t2)) + # Konstrukcja każdego wykresu
geom_point(color = „black”) + # Wykres
geom_smooth(method = „lm”,formula = y ~ x + I(x^3), size = 1) + # Dodana krzywa regesji dla drugiego wielomianu
theme_bw()+ # Ten wykres jest pokazny jak obrazek wyróżniający na górze tego wpisu 🙂
theme(legend.position = „bottom”) + # Ustawienie pozycji legendy
ggtitle(‚Zalezność miedzy doświadczeniem a zarobkami’) + # Ustawienie tytulu
labs( subtitle = „W poszczególnych okresach czasowych”, # Ustawienie podtytulu
caption = ‚Opracowanie na bazie danych „lwage”‚) + # Dopisanie jakiejś dodatkowej inforamcji
xlab(‚Doświadczenie w latach’) + # Nazwanie osi x
ylab(‚Zarobki (Logarytm)’) # Nazwanie osi y
W naszej analizie panelu możemy zrobic zupelnie inny wykres gdzie nadamy odcienie kropkom
naszedane %>% ggplot(mapping = aes(x = exp, y = lwage, color = ed)) +
geom_point() +
theme_bw()+
theme(legend.position = „bottom”) +
labs(tille = „costam”, subtitle = „Wykres2”)
naszedane %>% ggplot(mapping = aes(x = exp, y = lwage, color = t)) +
geom_point() +
theme_bw()+
theme(legend.position = „bottom”) + # Ustawienie pozycji legendy
ggtitle(‚Analiza zaleznosci miedzy’) + # Ustawienie tytulu
labs( subtitle = „Zaleznosc miedzy doswiadczeniem a zarobkami”, # Ustawienie podtytulu
caption = ‚Opracowanie na bazie danych lwage’) + # Dopisanie jakiejs dodatkowej inforamcji
xlab(‚Doswiadczenie’) + # Nazwanie osi x
ylab(‚Zarobki’) # Nazwanie osi y
naszedane %>% ggplot(mapping = aes(x = exp, y = lwage, color = wks)) +
geom_point() +
theme_bw()+
theme(legend.position = „bottom”) +
labs(tille = „costam”, subtitle = „Wykres2”)
naszedane %>% ggplot(mapping = aes(x = t, y = lwage)) +
geom_point() +
theme_bw()+
theme(legend.position = „bottom”) +
labs(tille = „costam”, subtitle = „Wykres2”)
# Wiecej wykresow w ggplot2 library
# TUTAJ klik
Analiza regresji panelowej w pakiecie „plm” w R.
# Y Zmienna zależna to logarytm zarobków
# X Zmienne niezależne to: exp = dowiadczenie w fimie, exp2 = to doswiadczenie calkowite, wks = przepracowane cale tygodnie w roku,
# Ed = edukacja (zmienna niezależna od czasu)
Y = cbind(naszedane$lwage) # Okreslenie zmiennej zaleznej w analizie panelowej
X = cbind(naszedane$exp2, naszedane$exp, naszedane$wks, naszedane$ed) #Okreslenie zmiennych w modelu panelowym.
# Ich kolejnosc bedzie odpowiadac kolejnosci wyswietlania w modelu
Ustawiamy dane jako panel. zmienna „id” w bazie danych to identyfikator obserwacji a „t” to nazwa zmiennej czasu
Dane_panelowe = pdata.frame(naszedane, index=c(„id”, „t”))
summary(X)
summary(Y)
# Dzieki tej funkcji wyswietlana jest pelna istotnosc statystyczna (a nie notacja naukowa jak np. 1e+48)
options(scipen=999)
# Przydaje sie kiedy wolimy znac dokladna istotnosc statystyczna/ Analiza regresji panelowej w pakiecie „plm” w R.
Rodzaje estymatorów w analizie regresji panelowej
- Pooling (analiza regresji panelowej nie uwzględniajaca różnic między badanymi obserwacjami)
- Between (analiza regresji panelowej biorąca pod uwagę zróżnicowanie między obserwacjami)
- Within (analiza regresji panelowej uwzględniające różnice wewnątrzosobnicze (wewnątrz obserwacji)
- First difference (analiza regresji panelowej uwzględniająca różnice między pomiarem wszcześniejszym, a późniejszym)
- Random ((analiza regresji panelowej, która traktuje zróżnicowanie między obserwacjami jako całkowicie losowe zjawisko i niezależne od zmiennych w modelu)
Wyszczególnione powyżej metody estymacji wyników analizy regresji panelowej przedstawiono poniżej:
Pooling estimator
# Pooling zaklada ze wartosc zmiennej zaleznej jest podobna u wszystkich obserwacji
# Klasyczne zalozenie dla danch indywidualnych ktore ignoruje fakt, ze dane maja charakter panelowy
pooling = plm(Y~X, data = Dane_panelowe, model = „pooling”) # Oszacowanie modelu
summary(pooling) # Podsumowanie modelu
Szkolenie Analiza Danych Panelowych w R Metodolog.pl
Pooling Model
Call:
plm(formula = Y ~ X, data = Dane_panelowe, model = „pooling”)
Balanced Panel: n = 595, T = 7, N = 4165
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-2.16057670 -0.25034526 0.00027256 0.26792139 2.12969386
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 4.907960667 0.067329675 72.8945 < 0.00000000000000022 ***
X1 -0.000715631 0.000052794 -13.5552 < 0.00000000000000022 ***
X2 0.044675051 0.002392860 18.6701 < 0.00000000000000022 ***
X3 0.005826979 0.001182650 4.9271 0.0000008673 ***
X4 0.076040693 0.002226597 34.1511 < 0.00000000000000022 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 886.9
Residual Sum of Squares: 635.41
R-Squared: 0.28356
Adj. R-Squared: 0.28287
F-statistic: 411.624 on 4 and 4160 DF, p-value: < 0.000000000000000222
Between estimator
# Between zaklada zróznicowanie miedzy osobami, czyli jak moje cechy różnia sie od twoich cech
between = plm(Y~X, data = Dane_panelowe, model = „between”) # Oszacowanie modelu
summary(between) # Podsumowanie modelu
Oneway (individual) effect Between Model
Call:
plm(formula = Y ~ X, data = Dane_panelowe, model = „between”)
Balanced Panel: n = 595, T = 7, N = 4165
Observations used in estimation: 595
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-0.978153 -0.220264 0.036574 0.250118 0.985629
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 4.68303917 0.21009890 22.2897 < 0.00000000000000022 ***
X1 -0.00063127 0.00012568 -5.0228 0.00000067570035 ***
X2 0.03815295 0.00569666 6.6974 0.00000000004953 ***
X3 0.01309028 0.00406592 3.2195 0.001355 **
X4 0.07378378 0.00489848 15.0626 < 0.00000000000000022 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 92.322
Residual Sum of Squares: 62.187
R-Squared: 0.32641
Adj. R-Squared: 0.32185
F-statistic: 71.4768 on 4 and 590 DF, p-value: < 0.000000000000000222
First Difference estimator
# Ciekawy estymator, ktory szacuje zroznicowanie w czasie na innej zasadzie.
# Powiedzmy, ze osoba ma zarobki w czasie t1, t2 i t2 wynoszace odpowiednio 1000, 2000, 4000
# Estymator ten ma postac t1 = 0, bo t1 – t0-1, t2 = t2 – t1, t3 t3 – t2, itd.
# W naszym przykladzie bedzie to, t1 = nie ma wartosci, ale t2 = 1000, t3 = 2000
# Ciekawe rozwiazanie jesli przewidujemy, ze nasze zjawisko dla kazdej obserwacji zmienia sie z kazda jednostka czasu.
firstdiff= plm(Y~X, data = Dane_panelowe, model = „fd”)
summary(firstdiff) #podsumowanie modelu
plm(formula = Y ~ X, data = Dane_panelowe, model = „fd”)
Balanced Panel: n = 595, T = 7, N = 4165
Observations used in estimation: 3570
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-2.1131555 -0.0654718 -0.0095751 0.0483881 2.3295637
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 0.11706540 0.00631057 18.5507 < 0.00000000000000022 ***
X1 -0.00053212 0.00013927 -3.8207 0.0001354 ***
X3 -0.00026826 0.00056483 -0.4749 0.6348525
— Szkolenie Analiza Danych Panelowych w R Metodolog.pl
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 118.06
Residual Sum of Squares: 117.58
R-Squared: 0.004108
Adj. R-Squared: 0.0035496
F-statistic: 7.35691 on 2 and 3567 DF, p-value: 0.0006479
Fixed = within estimator
# Within = fixed, zaklada zróznicowanie wewnarz osob, czyli, ze jest jakies nieobserwowane zroznicowanie
# miedzy obserwacjami wyrazone przez ich indywidualne stale,
# czyli np. kazda badana obserwacja rozni sie pod wzgledem zarobkow
# i ta roznica moze (ale nie musi) zalezec od zmiennych testowanych w modelu
# w takim modleu kazda obserwacja ma swoja indywidualna srednia zarobkow
# do tego modelu możemy wlaczyc zmienna czasu rozbita na serie zmiennych 0-1 jesli nas to interesuje
fixed = plm(Y~X, data = Dane_panelowe, model = „within”) # Pszacowanie modelu
summary(fixed) # Podsumowanie modelu
fixef(fixed) # Ta funkcja pozwala nam na wyswietlenie srednich zarobkow dla kazdej osoby
# Zauwazmy ze zmienna ed zostala wyrzucona z modelu bo jej zmiennosc byla zerowa
# Wyksztalcenie osob nie zmienialo sie w czasie, miedzy osobami tak, ale w ich indywidualnym czasie nie.
plm(formula = Y ~ X, data = Dane_panelowe, model = „within”)
Balanced Panel: n = 595, T = 7, N = 4165
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-1.8120879 -0.0511128 0.0037112 0.0614250 1.9434065
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
X1 -0.000424369 0.000054632 -7.7678 0.00000000000001036 ***
X2 0.113787860 0.002468885 46.0888 < 0.00000000000000022 ***
X3 0.000835878 0.000599673 1.3939 0.1634
—Szkolenie Analiza Danych Panelowych w R Metodolog.pl
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 240.65
Residual Sum of Squares: 82.632
R-Squared: 0.65663
Adj. R-Squared: 0.59916
F-statistic: 2273.74 on 3 and 3567 DF, p-value: < 0.000000000000000222
Random estimator
# Zaklada ze roznice miedzy osobami w czasie nie zaleza od zmiennych testowanych w modelu
# Analiza ta wlacza zmiennosc wynikajaca z roznic miedzy osobami jako zmiennosc losowa
# Czyli losowe roznie miedzy osobami staja sie w tym modelu czescia skladnika losowego
# Reandom estymator zwraca spojne wyniki dopiero jesli efekt losowy jest duzy, a individual maly.
random = plm(Y~X, data = Dane_panelowe, model = „random”)
summary(random)
# Wspolczynnik idiosyncratic w summary wskazuje na to ile wariancji
# niezaleznej od zmiennych w modelu jest wyjasnione roznicami miedzy obseracjami.
# Chodzi o to, ze obserwacje moga sie roznic pod wzgledem zmiennych
# innych niz w modelu (nie znamy tych zmiennych, ale wiemy ze tak jest)
# i to jest uchwycona osobliwa losowa zmiennosc #Szkolenie Analiza Danych Panelowych w R Metodolog.pl
# Natmiast wspolczynnik individual wskazuje ile wariancji zmiennej jest wyjasnione efektami indywidualnymi
# theta wskazuje na proporcje tych wskaznikow,
# im blizej 1 tym wiecej wariancji jest wyjasniane przez efekty indywidualne, a nie losowe
Call:
plm(formula = Y ~ X, data = Dane_panelowe, model = „random”)
Balanced Panel: n = 595, T = 7, N = 4165
Effects:
var std.dev share
idiosyncratic 0.02317 0.15220 0.185
individual 0.10209 0.31952 0.815
theta: 0.8228
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-2.0439676 -0.1057048 0.0070992 0.1147499 2.0875839
Coefficients:
Estimate Std. Error z-value Pr(>|z|)
(Intercept) 3.829366113 0.093633576 40.8974 <0.0000000000000002 ***
X1 -0.000772565 0.000062262 -12.4083 <0.0000000000000002 ***
X2 0.088860947 0.002817760 31.5360 <0.0000000000000002 ***
X3 0.000965772 0.000743288 1.2993 0.1938
X4 0.111709951 0.006057161 18.4426 <0.0000000000000002 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 260.94
Residual Sum of Squares: 151.35
R-Squared: 0.42
Adj. R-Squared: 0.41945
Chisq: 3012.45 on 4 DF, p-value: < 0.000000000000000222
Szkolenie Analiza Danych Panelowych w R Metodolog.pl
Testowanie wyboru odpowiedniego modelu regresji panelowej w R
# random effects vs ols Breuch Pagan Agrange Multiplier Test. Jesli jest istotny to model random jest lepszy niz OLS.
plmtest(pooling)
# fixed effects vs ols F test for individual effects test. Jesli jest istotny wtedy model fixed jest bardziej dopasowany niz OLS.
pFtest(fixed,pooling)
# Hausman test for fixed vs random effects model. Jesli jest itotny to wybieramy model fixed, jesli nie to wybieramy random effects.
phtest(random,fixed)
#Lagrange Multiplier Test – time effects (Breusch-Pagan) for balanced panels = Weryfikuje hipoteze o tym czy wartosci zmiennej zaleznej sa zalezne od czasu.
plmtest(fixed,c(„time”), type = („bp”))
# Powyzszy test potwierdza to co zobaczylismy na wykresie na poczatku
plotmeans(lwage~t, main=”Zmiennosc Y w czasie”, data = naszedane)
Szkolenie Analiza Danych Panelowych w R Metodolog.pl
Testowanie zalozenia o heteroscedastycznosci w modelu regresji panelowej
# chcemy sprawdzic heteroscedastycznosc, czyli zjawisko wystepowania rownej wariancji odchylen skladnika losowego
# od wwynikow zminnej zaleznej
# Możemy wykonać to dla kazdej zmiennej w modelu
# Jesli jest istotny to znaczy, ze zachodzi zajawisko heteroscedastycznosci
bptest(lwage ~ ed + factor(id), data = naszedane , studentize=F)
bptest(lwage ~ exp + factor(id), data = naszedane , studentize=F)
bptest(lwage ~ t + factor(id), data = naszedane , studentize=F)
bptest(lwage ~ wks + factor(id), data = naszedane , studentize=F)
bptest(lwage ~ exp2 + factor(id), data = naszedane , studentize=F)
Możemy zwizualizować sobie heteroscedacstyczność za pomocą wykresów rysowanych przez pakiet ggplot2
#zapisujemy reszty z wynikow analizy fixed
resid = fixed$residuals
#tworzymy ramke danych
resztyframe= cbind(resid,naszedane$lwage)
#zapisujemy ja jako obiekt dataframe
resztyframe = as.data.frame(resztyframe)
resztyframe %>% ggplot(aes(y = resid, x = V2)) + #zaciagamy z bazy danych resztyframe
geom_point(color = „red”) + # wykres
geom_smooth(method = „lm”)
#analiza dla pooling
#zapisujemy reszty z wynikow analizy pooling
resid2 = pooling$residuals
#tworzymy ramke danych
resztyframe2= cbind(resid2,naszedane$lwage)
#zapisujemy ja jako obiekt dataframe
resztyframe2 = as.data.frame(resztyframe2)
resztyframe2 %>% ggplot(aes(y = resid2, x = V2)) + #zaciagamy z bazy danych resztyframe
#V3 to jest zmienna lwege w nowym data framie
geom_point(color = „red”) + # wykres
geom_smooth(method = „lm”)
Wykonumeny sobie to samo dla analizy analizy panelowej estymatorem random
#analiza dla random
#zapisujemy reszty z wynikow analizy random
resid3 = random$residuals
#tworzymy ramke danych
resztyframe3= cbind(resid3,naszedane$lwage)
#zapisujemy ja jako obiekt dataframe
resztyframe3 = as.data.frame(resztyframe3)
resztyframe3 %>% ggplot(aes(y = resid3, x = V2)) + #zaciagamy z bazy danych resztyframe
geom_point(color = „red”) + # wykres
geom_smooth(method = „lm”)
Korygowanie oszacowań błędów standardowych ze względu na heteroscedastyczność w modelu random
W modelu panelowym możemy nieco skorygować błedy standardowe dzięki różnym opcjom „HC”
random = plm(Y~X, data = Dane_panelowe, model = „random”)
summary(random)
coeftest(random, vcovHC)
coeftest(random, vcovHC(random, type = „HC0”)) # heteroskedastycznie spójne
coeftest(random, vcovHC(random, type = „HC1”)) # Rekomendowane dla malych probek
coeftest(random, vcovHC(random, type = „HC3”)) # Rekomendowane dla malych probek i daje male znaczenie obserwacjom wplywowym
coeftest(random, vcovHC(random, type = „HC4”)) # Rekomendowane dla malych probek ze obserwacjami mocno wplywajacymi
Korygowanie oszacowań błędów standardowych ze wzgledu na heteroscedastyczność w modelu fixed
Tutaj możemy zrobić to analogicznie dla modelu fixed
fixed = plm(Y~X, data = Dane_panelowe, model = „within”)
summary(fixed)
coeftest(fixed, vcovHC)
coeftest(fixed, vcovHC(fixed, method = „arellano”))
coeftest(fixed, vcovHC(fixed, type = „HC3”))
Szkolenie Analiza Danych Panelowych w R Metodolog.pl
