Przygotowanie danych do Text Miningu.
- Dane
1.1. Dane do text miningu to w naszym przypadku wpisy z naukowego bloga Metodolog.pl. Pozyskamy je, kopiując interesujące elementy każdego z wpisów. Pojedynczą obserwacją będzie zatem wpis na blogu Metodolog.pl, a cechami każdej z obserwacji: 1) data zamieszczenia; 2) tytuł; 3) treść wpisu.
Struktura wpisów sprawia, że trudno wyciągnąć z nich więcej odrębnych danych – nie posiadają one na przykład osobnej rubryki zawierającej informację o autorze lub konkretnej kategorii artykułu, nie znajdziemy pod wpisami komentarzy czytających.
1.2. Wszelkie dane najwygodniej umieścić w arkuszu kalkulacyjnym, np. Microsoft Excel. Po pierwsze, pozwoli nam to na łatwe kopiowanie, magazynowanie i przeglądanie danych oraz umożliwi wstępną obróbkę danych. Po drugie, wiele programów do analizy danych (w tym RStudio oraz Orange) umożliwia zaimportowanie danych wprost z arkusza kalkulacyjnego. Po trzecie, posiadając jako źródło plik arkusza kalkulacyjnego, bezpośrednio utworzyć można plik .csv, który jest powszechnie stosowanym formatem przechowywania danych statystycznych.
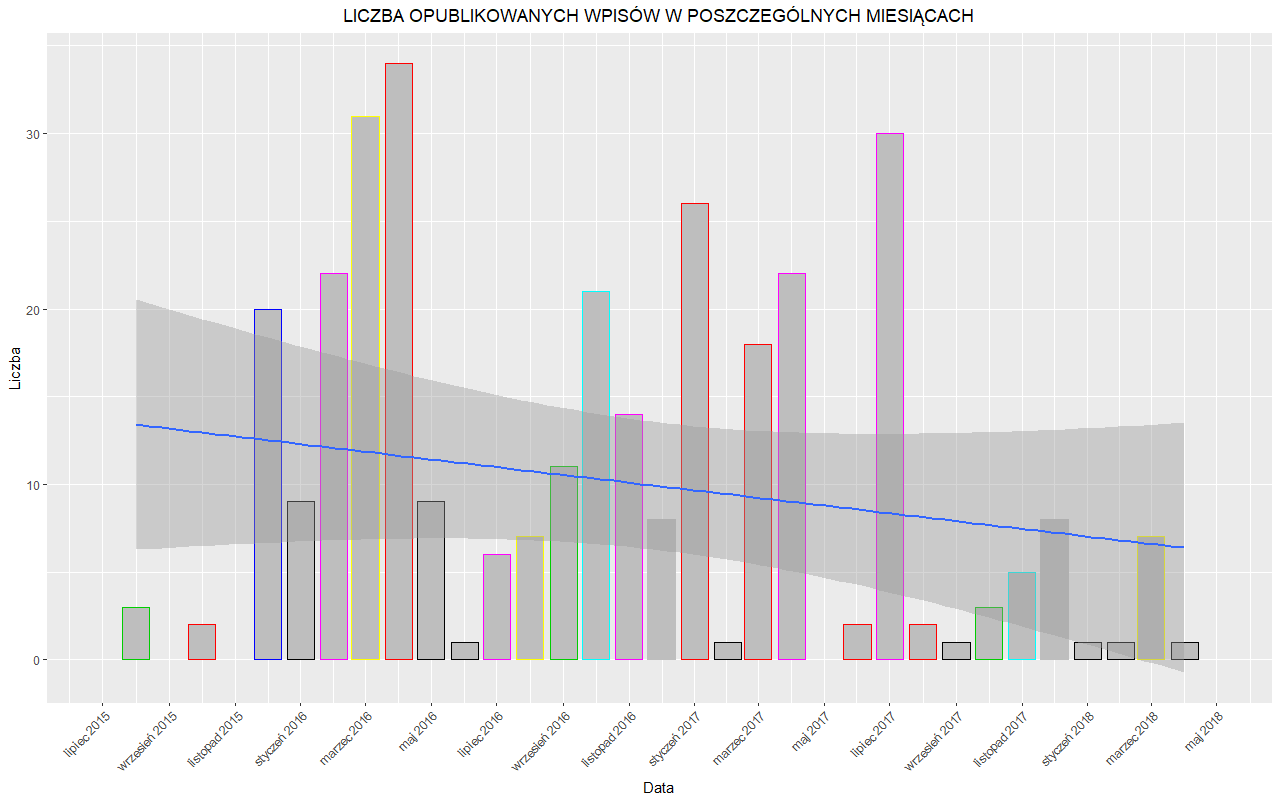
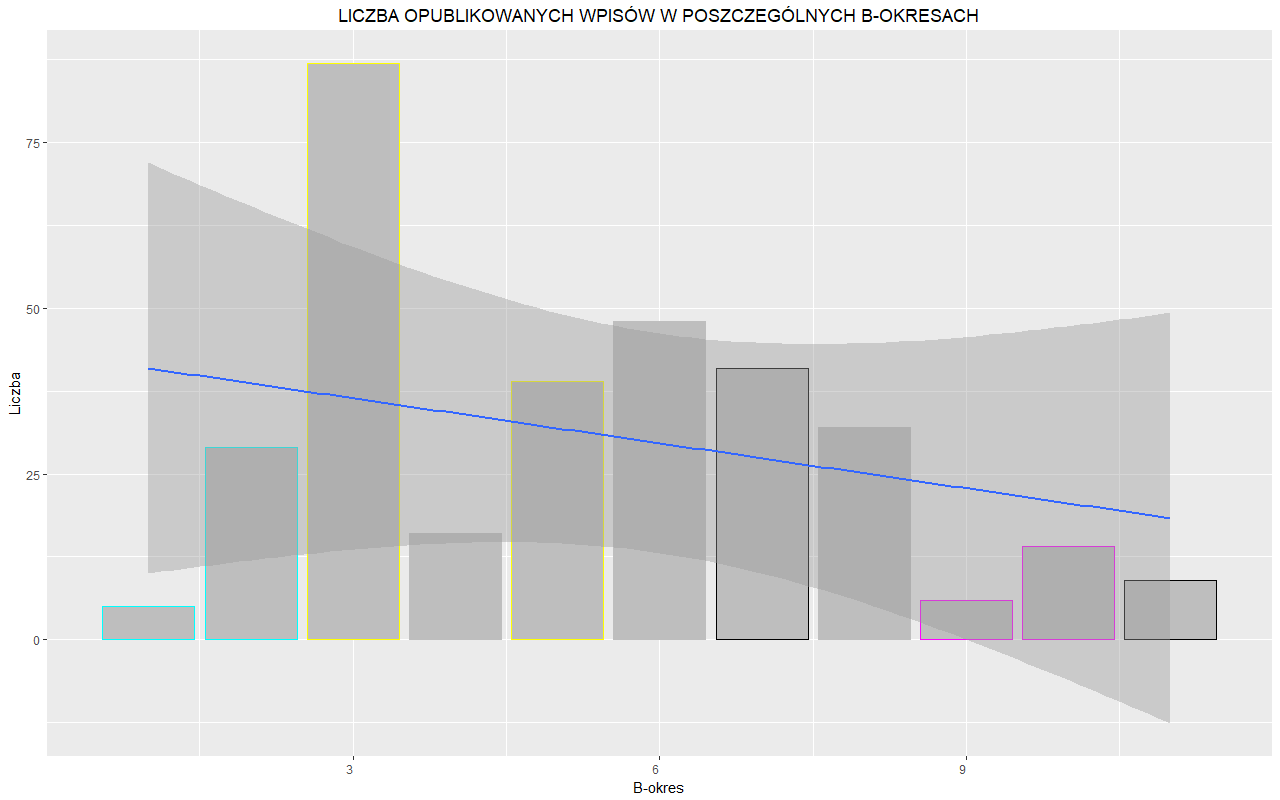
1.3. Ostatecznie, po zamieszczeniu w arkuszu interesujących nas danych, otrzymujemy 328 obserwacji. Kilka z nich powinno zwrócić naszą uwagę:
- a) w kilku przypadkach treść wpisu zawarta była w obrazku, czyli w perspektywie przeprowadzanego przez nas text miningu była nieanalizowalna; oczywiście tytuł tego wpisu był już typową daną tekstową – te wpisy potraktujemy zatem jako istniejące, ale niezawierające tekstu.
- b) w dwóch przypadkach treść wpisu składała się z ponad 32767 znaków, czyli przekraczały maksymalną pojemność jednej komórki arkusza kalkulacyjnego w programie Excel. To nie jedyny problem – taka ilość tekstu sprawiała, że wpisy te były swoistymi obserwacjami odstającymi – uwzględnienie ich w dalszej analizie skutkowałoby tym, że sumaryczna częstość występowania poszczególnych słów w nieproporcjonalnie dużym stopniu zależałaby od tych dwóch wpisów, co mogłoby utrudnić uzyskanie informacji oddających ogólną charakterystykę wpisów na stronie. Te dwie obserwacje zupełnie eliminujemy.
1.4. Posiadając już zbiorczo zgromadzoną zawartość wszystkich wpisów z bloga naukowego Metodolog.pl, można przejść do przetłumaczenia tekstu i tytułów na język angielski. Dlaczego jest to konieczne? Otóż niestety narzędzia wspomagające analizę tekstu, takiej jak słowniki stop words oraz stemmery (patrz niżej), najlepiej współpracują z tekstem w języku angielskim, a trudno znaleźć jakiekolwiek obsługujące język polski. Dlatego przetłumaczenie jest niezbędne do przeprowadzenia efektywnej analizy tekstu. Oczywiście w tym celu nie będziemy zatrudniać tłumacza przysięgłego, tylko wspomożemy się ogólnodostępnym tłumaczem internetowym – w naszym przypadku będzie to Google Translator.
Powstać może pytanie: czy znaczenia słów nie zostaną zmienione, czy tłumaczenie nie będzie niskiej jakości? Oczywiście, że będzie ono niewystarczające do komfortowego czytania takiego tekstu. Jednak tłumaczenie takie jest wystarczającej jakości, aby wykorzystać je do analizy tekstu. Dzieje się tak ze względu na kilka ważnych cech, które warto wyszczególnić. Po pierwsze, w analizie tekstu nie zależy nam na braku błędów językowych, składniowych czy stylistycznych w tłumaczeniu, ponieważ strukturę gramatyczną wypowiedzi i tak pomijamy. W analizie interesujące są tylko pojedyncze, powiązane z samoistnym znaczeniem słowa – a nie na przykład zachowanie stylu oryginału. Po drugie, widząc poważne błędu w tłumaczeniu łatwo nie zauważyć, że są jednak one dość rzadkie, jeśli spojrzeć z czysto statystycznego punktu widzenia. Jako ludzie biegle posługujący się danym językiem, jesteśmy bardzo wyczuleni na poważniejsze błędy językowe. Dlatego nawet, gdy stanowią one niewielki odsetek tekstu, będziemy traktować go jako niskiej jakości. Jednak te kilka procent błędów nie będzie znacząco wpływać na analizę ilościową – ogólna charakterystyka tekstu zostanie zachowana. Po trzecie, tłumacze internetowe, takie jak Google Translate, od czasu znaczącego unowocześnienia ich algorytmów, radzą sobie całkiem przyzwoicie z „suchymi” tekstami (w których walor stylistyczny oraz abstrakcyjne, liryczne, wysublimowane językowo konstrukcje nie mają takiego znaczenia) – a w przeważającej części to z takimi tekstami będziemy mieli do czynienia w ramach naszej analizy.
Na szczęście nie musimy każdego tekstu tłumaczyć osobno. Przy pomocy funkcji napisanej w języku Visual Basic for Application tłumaczenie z polskiego na angielski w arkuszu kalkulacyjnym Excel możemy zautomatyzować. Funkcja ta pozwoli na tłumaczenie tekstu o objętości do 10 000 znaków (ze spacjami). Pozostałe teksty stanowią niewielki odsetek całości i możemy przetłumaczyć je ręcznie. Kod funkcji w języku VBA widnieje poniżej (bazuje on na kodzie proponowanym pod adresem https://analystcave.com/excel-google-translate-functionality/).
Function ConvertToGet(val As String)
val = Replace(val, ” „, „+”)
val = Replace(val, vbNewLine, „+”)
val = Replace(val, „(„, „%28”)
val = Replace(val, „)”, „%29”)
ConvertToGet = val
End Function
Function Clean(val As String)
val = Replace(val, „"”, „”””)
val = Replace(val, „%2C”, „,”)
val = Replace(val, „'”, „‚”)
Clean = val
End Function
Public Function RegexExecute(str As String, reg As String, _
Optional matchIndex As Long, _
Optional subMatchIndex As Long) As String
On Error GoTo ErrHandl
Set regex = CreateObject(„VBScript.RegExp”): regex.Pattern = reg
regex.Global = Not (matchIndex = 0 And subMatchIndex = 0) ‚For efficiency
If regex.Test(str) Then
Set matches = regex.Execute(str)
RegexExecute = matches(matchIndex).SubMatches(subMatchIndex)
Exit Function
End If
ErrHandl:
RegexExecute = CVErr(xlErrValue)
End Function
Public Function TLUMACZ(rng As Range)
Dim getParam As String, trans As String, objHTTP As Object, URL As String
Set objHTTP = CreateObject(„MSXML2.ServerXMLHTTP”)
getParam = ConvertToGet(rng.Value)
URL = „https://translate.google.pl/m?hl=pl&sl=pl&tl=en&ie=UTF-8&prev=_m&q=” & getParam
objHTTP.Open „GET”, URL, False
objHTTP.setRequestHeader „User-Agent”, „Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)”
objHTTP.send („”)
If InStr(objHTTP.responseText, „div dir=””ltr”””) > 0 Then
trans = RegexExecute(objHTTP.responseText, „div[^””]*?””ltr””.*?>(.+?)</div>”)
TLUMACZ = Clean(trans)
Else
TLUMACZ = CVErr(xlErrValue)
End If
End Function
1.5. Ostatecznie ogólna struktura tabeli zawierającej posiadane przez nas dane prezentują się następująco:
| L.p. |
Data |
Tytuł_pl |
Treść_pl |
Tytuł_ang |
Treść_ang |
| 1 |
<data> |
<Tytuł wpisu> |
<Treść wpisu> |
<TLUMACZ(Tytuł_pl)> |
<TLUMACZ(Treść_pl)> |
| … |
… |
… |
… |
… |
… |
| 326 |
<data> |
<Tytuł wpisu> |
<Treść wpisu> |
<TLUMACZ(Tytuł_pl)> |
<TLUMACZ(Treść_pl)> |
Jeśli nie zamierzamy korzystać z polskojęzycznych, nieprzetłumaczonych części, warto ramkę zredukować – będzie wtedy zajmowała znacząco mniej miejsca:
| L.p. |
Data |
Tytuł_ang |
Treść_ang |
| 1 |
<data> |
<Tytuł wpisu ang.> |
<Treść wpisu ang.> |
| … |
… |
… |
… |
| 326 |
<data> |
<Tytuł wpisu ang.> |
<Treść wpisu ang.> |
Analizy oraz wpis sporządził Pan Andrzej Porębski. Dziękujemy!