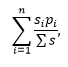Wykorzystanie IRT (item response theory) do adaptacyjnych testów komputerowych (CAT) – detaliczna diagnostyka jakości kwestionariusza i redukcja czasu badania

Plan artykułu:
- Czym jest IRT?
- Wstęp – definicja
- Wyjaśnienie na przykładzie – objaśnienie różnic między klasycznym podejściem a podejściem IRT.
- Jakie są zalety wdrażania IRT
- Dokładna analiza struktury testu – jakie dodatkowe informacje o teście zyskujemy dzięki wykorzystaniu IRT
- Tworzenie adaptacyjnych testów komputerowych CAT (computer adaptive testing) – co daje możliwości implementacji IRT do testowania adaptatywnego
- Jakie wymogi musimy spełnić by stworzyć test CAT – czyli łyżka dziegciu w beczce miodu.
Czym jest IRT?
1a) Wstęp.
IRT (ang. Item Response Theory) to w psychometrii paradygmat projektowania, analizowania oraz punktowania testów/kwestionariuszy mierzących zdolności, nastroje i inne zmienne. W odróżnieniu od alternatywnych, prostszych podejść dla tworzenia skal i oceniania odpowiedzi kwestionariuszowych (np. do powszechnie używanego podejścia nazywanego Klasyczną Teorią Testu) nie zakłada, że wszystkie pozycje mierzą ten sam stopień natężenia cechy i charakteryzują się taką samą jakością. Jak lepiej to zrozumieć?
1b) Wyjaśnienie na przykładzie.
Na potrzeby wyjaśnienia stworzyłem przykład testu poznawczego (test wiedzy matematycznej) oraz przykład testu afektywnego (test satysfakcji z życia).
Test poznawczy: Badanemu zadawane jest pytanie dotyczące jego wiedzy matematycznej. Są tylko dwie możliwe opcje odpowiedzi: badany odpowie poprawnie bądź nie.
| Test wiedzy matematycznej | Odp. niepoprawna | Odp. poprawna |
| A. 2 + 2 = ? | ||
| B. 8+8*8=? | ||
| C. (3!-4)3+1/(24) |
Analizując wyniki dla powyższych testów zgodnie z klasycznym podejściem sumujemy punktacje odpowiedzi badanego na te 3 pytania otrzymując wynik ogólny przedstawiających wskaźnik poziomu wiedzy matematycznej respondenta. Taki sposób wyliczania wyniku wymaga założenia, że pozycje są identyczne pod kątem ważności mierzonej cechy, tzn. wzór odpowiedzi badanego nr 1: A-1 B-1 C-0 (suma punktów = 2) będzie zwracał taki sam wynik poziomu wiedzy matematycznej co wzór badanego nr 2: A-1 B-0 C-1 (suma punktów = 2) dlatego chcąc nie chcąc zakładamy, że pozycje są równie ważne.
A jak by to wyglądało w przypadku podejścia IRT?
Po pierwsze dzięki IRT moglibyśmy otrzymać 4 informacje o każdej z pozycji testowych. Tymi informacjami są:
- Dyskryminacja pozycji testowej (oznaczana symbolem „a”) – informacja o tym jak dobrze dana pozycja rozróżnia osoby o niższym natężeniu cechy od osób o wyższym natężeniu cechy. Weźmy na warsztat pozycje A. Gdyby okazało się, że ta pozycja doskonale rozdziela grupę respondentów na tych którzy nie skończyli przedszkola (osoby, które nie odpowiedziały poprawnie na pytanie) od tych którzy przedszkole ukończyli (wszyscy badani po skończeniu przedszkola odpowiadali poprawnie) wtedy byśmy mogli stwierdzić że pozycja charakteryzuje się wysokim parametr dyskryminacji. Innymi słowy, pozycja wysoce dyskryminująca, nie ważne łatwa, umiarkowana czy trudna, bardzo dokładnie rozdziela badanych na tych o mniejszym i o większym natężeniu analizowanej cechy. Wysoka dyskryminacja jest pożądaną cechą i IRT umożliwia diagnozę pozycji pod tym kątem, co w przypadku klasycznego podejścia jest całkowicie zaniedbywane.
- Trudność pozycji testowej (oznaczana symbolem „b”) – jak dana pozycja wypada na tle innych pod kątem natężenia cechy którą mierzy – czy badani w większości przypadków odpowiadali poprawnie na tę pozycję czy nie. W przykładowym teście wiedzy matematycznej najprostsza (o najniższej wartości parametru b) będzie oczywiście pozycja A., później B zaś najtrudniejsza C. IRT pozwala na diagnozę parametru trudności każdej pozycji co w przypadku klasycznego podejścia jest zaniedbywane.
- Dolna asymptota pozycji testowej („c”)
- Górna asymptota pozycji testowej („d”)
Parametry „c” i „d” są rzadziej wykorzystywane od „a” i „b”, zaś ich wytłumaczenie wymagałoby trochę bardziej złożonych wyjaśnień, dlatego znalazły się one poza zakresem tego wpisu.
Jeżeli są tu z nami osoby zajmujące się wykorzystywaniem testów afektywnych (tzn. takich w których nie ma zły/dobrych odpowiedzi, bo badani opisują najczęściej siebie, bądź innych w kontekście stanów psychicznych) to się świetnie składa, bo IRT tak samo doskonale sprawdza się w przypadku testów afektywnych. Innymi słowy informacje o parametrach dyskryminacji i trudności moglibyśmy uzyskać równie dobrze dla pytań z poniższej, wymyślonej skali satysfakcji z życia.
Test afektywny: Badany proszony jest by odpowiedział na 3 poniższe pytania na 5 stopniowe skali Likerta, gdzie 5 oznacza zdecydowanie się zgadzam, zaś 1 zdecydowanie się nie zgadzam.
| Treść pytania SKALI SATYSFAKCJI Z ŻYCIA | 1 | 2 | 3 | 4 | 5 |
| A. Moje życie jest idealne pod każdym względem. | |||||
| B. Gdy wstaje nad ranem i myślę o nadchodzącym dniu, wypełnia mnie optymizm. | |||||
| C. Lubię moje życie. |
Podsumowując wykorzystując IRT nie zakładamy, że wszystkie pozycje są takie same (klasyczne podejście) ale jesteśmy w stanie każdą z nich opisać pod kątem dyskryminacji i trudności. Jak wielkie jesteśmy w stanie z tego czerpać korzyści opisuję dalej.
Jakie są zalety wdrażania IRT
2a) Dokładna analiza struktury testu.
Jeżeli chcemy by test zawierał pozycje odnoszące się zarówno do niskiego natężenia analizowanej cechy (np. niskiego poziomu wiedzy matematycznej) jak i do wysokiego poziomu, przy jednoczesnej kontroli jakości tych pozycji (dyskryminacja) nie mamy innej opcji jak skorzystać z IRT. Dodatkowo możemy tak dobierać sobie pozycje testowe by nasz test charakteryzował się dokładnie taką rzetelnością jakbyśmy oczekiwali.
2b) Tworzenie adaptacyjnych testów komputerowych (computer adaptive testing)
Najciekawsze zaczyna się jednak teraz.
Dzięki podstawom teoretycznym IRT możliwe jest tworzenie adaptacyjnych testów komputerowych (w skrócie CAT – computer adaptive testing) tzn. testów samodopasowujący się do wiedzy badanego dzięki czemu istotnie redukujących czas trwania badania. W jaki sposób? Omówię to na przykładzie testów inteligencji:
Standardowe testy inteligencji zaczynają się od bardzo prostych pytań, przechodzą przez umiarkowane aż po jakiś 20/25 minut przejść do wyjątkowo skomplikowanych zadań, które jedynie nieliczni są w stanie rozwiązać. Procedura ta jest tak pomyślana, by jeden test wystarczył by móc oceniać inteligencję na pełnym wymiarze jej continuum. Jednakże tracimy dużo czasu, gdy osoby bardzo inteligentne muszą przechodzić przez szereg prostych dla nich zadań by na sam koniec zmierzyć się z pytaniami stanowiącymi dla nich wyzwanie.
CAT sprytnie omija ten problem. W jaki sposób? Algorytm CAT wyliczają najbardziej prawdopodobny poziom cechy badanego na podstawie dotychczasowego wzoru odpowiedzi. Zwyczajowo zaczyna się badanie od wylosowanie pozycji testowej o umiarkowanym poziomie trudności. Jeżeli badany odpowiedzi na nią poprawnie, algorytm wylicza najbardziej prawdopodobny poziom badanego i losuje taką pozycję, która będzie najlepiej dopasowano do obecnie wyliczonego poziomu wiedzy badanego. Najlepiej dopasowany poziom trudności to taki, w którym badany ma 50% szans na poprawną odpowiedź. Tzn. jeżeli zakładamy, że mamy do czynienia z dzieckiem w wieku około przedszkolnym zadamy mu pytanie „A” z testu wiedzy matematycznej, jeżeli odpowie poprawnie będziemy mogli założyć, że raczej ukończyło przedszkole, jeżeli nie odpowie poprawnie założymy na odwrót. Nie byłoby sensu osobie w wieku około przedszkolnym zadawać pytania „C”, gdyż łatwo przewidywalny fakt błędnej odpowiedzi nie dostarczyłby nam informacji czy jest ona lepsza czy gorsza od swoich rówieśników, bo na pewno odpowiedziałaby źle.
Podsumowując dzięki CAT możemy zredukować czas trwania testu około 50% przy zachowaniu tych samych wartości rzetelności/jakości testu.
Takie testy mniej nużą badanych, pozwalając na utrzymanie motywacji na wysokim poziomie przez cały okres trwania badania, zwracając wyniki mniej obciążone o błąd pomiaru.
Jakie wymogi musimy spełnić by stworzyć test CAT?
Tworzenie testu CAT jest jednak bardziej wymagające od klasycznego podejścia. Przede wszystkim musimy posiadać dużą bazę pozycji testowych z których algorytm CAT będzie losował pytania. W zależności od typu testu i mierzonej cechy baza pozycji testowych powinna być od 3 do 10 razy większa od docelowej długości testu. Jeżeli planujemy badać wiedzę matematyczną przy użyciu 10 pozycji testowych (nie chcemy używać większej ilości pozycji, bo zależy nam na czasie) wtedy baza danych powinna zawierać od 30 do 100 pozycji testowych.
W odróżnieniu od podejścia klasycznego w którym po stworzeniu pozycji testowych w zasadzie od razu możemy przejść do ich użycia, w przypadku CAT najpierw musimy przebadać skonstruowane pozycje testowe na odpowiednio dużej grupie badanych. Wielkość te grupy zależy od wielu czynników i każdorazowo jest oszacowywana indywidualnie do potrzeb danego testu.
Autor tekstu:
Łukasz Rąbalski
spec. ds. Analiz Statystycznych i Metodologii Badań