Hipoteza statystyczna – Obiegowa opinia, że za pomocą statystyki można udowodnić wszystko (choć sąd ten wynika z innych przyczyn, o czym za chwilę), jest zupełną nieprawdą, gdyż za pomocą metod statystycznych nie jesteśmy w stanie udowodnić prawdziwości jakiejkolwiek hipotezy i nigdy nie udowadniamy prawdziwości czy nieprawdziwości jakiejkolwiek tezy. Stosując statystykę, uzyskujemy wiedzę użyteczną (najczęściej także prawdziwą, choć nie zawsze).
Wracając do powszechnych opinii o statystyce, spotykamy również i takie:
statystyka to kłamstwa,
znam odpowiedź, dostarcz mi statystyk w celu jej uzasadnienia.
Wynikają one z tego, że istotnie używając niewłaściwych metod, czy wykorzystując tylko część i to tendencyjnie wybranych danych albo używając wymyślonych danych, możemy dowolnie wpływać na uzyskiwane rezultaty. Ale takie zjawiska występują w każdej dziedzinie ludzkiej działalności (np. statystyka medyczna). Lekarz wybierając niewłaściwy sposób leczenia, może spowodować śmierć pacjenta, piekarz używając niewłaściwej mąki upiecze zakalec. Te same prawa rządzą stosowaniem metod statystycznych. Każda metoda statystyczna ma leżący u jej podstaw zbiór założeń i pewien zakres stosowalności i poza ten zakres nie mamy prawa wyjść, aby nie fałszować rezultatów.
Więcej tego typu rozważań oraz mnóstwo przykładów zastosowań statystyki znajdzie czytelnik w książce Rao (1994).
W statystyce matematycznej wyróżniamy dwa główne działy, do których daje się zakwalifikować znakomitą większość wykorzystywanych metod: teoria estymacji i testowanie hipotez statystycznych. Poniżej sformułowane zostaną podstawowe pojęcia z zakresu teorii testowania hipotez statystycznych oraz teorii estymacji. Pojęcia te będą sformułowane w pełnej ogólności, aby można było pokazać istotę statystyki jako problematyki podejmowania decyzji.
Hipoteza statystyczna to każde przypuszczenie dotyczące rozkładu (rozkładów) prawdopodobieństwa badanej zmiennej losowej (zmiennych losowych). Przypuszczenie to może dotyczyć parametru (parametrów) rozkładu prawdopodobieństwa albo postaci tegoż rozkładu. Hipoteza statystyczna dotyczy teoretycznej kategorii badania, a nie wyników uzyskanych z próby. Hipoteza statystyczna formułowana jest w terminach prawdziwych (choć nam nieznanych) wartości parametrów rozkładu bądź postaci rozkładu prawdopodobieństwa, czyli dotyczy prawdziwych wartości parametrów czy postaci rozkładu, a nie rezultatów uzyskanych na podstawie obserwacji (pomiarów) elementów próby. Wyniki liczbowe uzyskane z próby są podstawą do weryfikacji hipotezy statystycznej. Na podstawie próby, uogólniając jej wynik, formułujemy pewne sądy dotyczące ogólniejszej rzeczywistości – jest to istota metod indukcyjnych (rozumowania indukcyjnego).
Przykład 1. Hipoteza statystyczna
Porównujemy dwie grupy osób pod względem cechy, którą można mierzyć (masa ciała, wzrost, wskaźnik inteligencji, poziom cholesterolu całkowitego w surowicy krwi itp.). Stawiamy (formułujemy) hipotezę, że wartości oczekiwane tejże zmiennej są takie same w obu grupach, tj.:
P1= P2
Podkreślam: hipoteza jest sformułowana w terminach „prawdziwych” wartości parametru, dlatego w sformułowaniu hipotezy występują oznaczenia, jakich używaliśmy dla wartości oczekiwanej. Natomiast sprawdzanie, czyli weryfikację hipotezy, przeprowadza się na podstawie wyników uzyskanych w próbie i parametry obliczane na podstawie próby oznaczane będą inaczej.
Przykład 2. Hipoteza statystyczna
Twierdzimy, że badana przez nas cecha (zmienna losowa) ma rozkład normalny. Ta hipoteza jest sformułowana w terminach postaci funkcyjnej rozkładu prawdopodobieństwa, ale znów dotyczy ona „prawdziwej zmiennej”, „teoretycznej zmiennej losowej”
Test statystyczny to reguła postępowania, która na podstawie wyników próby ma doprowadzić do PODJĘCIA PRZEZ NAS DECYZJI przyjęcia lub odrzucenia postawionej hipotezy statystycznej. Przyjęcie hipotezy oznacza uznanie jej za prawdziwą, natomiast odrzucenie oznacza, iż uznajemy ją za fałszywą. Na podstawie przeprowadzonego testu statystycznego nie jesteśmy w stanie stwierdzić, czy nasza hipoteza statystyczna jest prawdziwa czy fałszywa. Badacz podejmuje decyzję o prawdziwości bądź fałszywości badanej hipotezy, ale jest to jego subiektywna decyzja, która nie musi być poprawna. Na szczęście ta subiektywna decyzja jest obiektywizowana poprzez ocenę wielkości niepewności, tj. poprzez ocenę prawdopodobieństwa podjęcia decyzji błędnej.
Statystyka – Pierwsze i najpowszechniej znane to:
gromadzenie, prezentacja i analiza materiałów liczbowych (statystyki urzędowe, rejestry administracyjne itp.); tego typu statystykę uprawiano od bardzo dawna.
Drugie znaczenie, znajdujące zastosowanie w statystyce matematycznej, to: • statystykę nazywana jest każda mierzalna funkcja zmiennych losowych. Oczywiście statystyka też jest zmienną losową; warunek mierzalności funkcji nie jest tutaj żadnym ograniczeniem, gdyż w ramach tego wykładu każda z używanych przez nas funkcji zmiennych losowych jest funkcją mierzalną, oraz trzecie znaczenie:
#statystyka jest rozumiana jako zespół metod służących do analizy danych, umożliwiających znajdowanie pewnych prawidłowości czy uogólnianie zależności. Statystyka w tym znaczeniu nazywana bywa statystyką matematyczną.
Warto sięgnąć do historii zbierania danych i przytoczyć kilka z interesujących systemów opisanych przez Rao (1994).
statystyka – Chiny – 2000 lat p.n.e., w czasach dynastii Sia przeprowadzano spisy ludności. Za dynastii Czou (1122-256 p.n.e.) ustanowiono oficjalne stanowisko odpowiedzialnego za prace statystyczne (księgowego). Interesowano się wówczas takimi sprawami, jak np. ile rodzin posiada ziemię i domy? Jakimi zasobami żywności dysponuje rodzina? Ile jest wdowców, wdów, sierot, inwalidów i chorych? Ilu mężczyzn zdolnych do służby wojskowej można zmobilizować w nagłym przypadku? Ilu ludzi potrzebnych by było do realizacji różnych ważnych dla państwa przedsięwzięć? Jak liczne i jak zamożne są pewne mniejszości, które mogłyby czuć się dotknięte planowanymi zmianami w prawach o własności lub o związkach małżeńskich? Jaka jest zdolność podatkowa kraju, prowincji własnych i sąsiednich? Jak widać z katalogu przykładowych pytań, zbierane dane dostarczały bardzo ważnych informacji umożliwiających sprawne zarządzanie państwem. Współcześnie nic więcej w tej materii nie wymyślono.
Statystyka – W Europie rzymski spis ludności został ustanowiony przez szóstego króla Rzymu Serwiusza Tuliusza (578-543 p.n.e.). W ramach tego systemu, w pięcioletnich odstępach czasu sporządzano rejestr obywateli i ich własności w celach podatkowych i w celu wyznaczenia liczby mężczyzn zdolnych do służby wojskowej.
statystyka – W Indiach skomplikowany system rejestrów administracyjnych lub statystyk urzędowych istniał już przed 300 r. p.n.e. Odpowiedni rachmistrz (rachmistrz wiejski) miał obowiązek prowadzić wszelkiego rodzaju rejestry dotyczące ludności, użytkowania ziemi, produkcji rolnej itp. Zaliczał on domy do płacących albo niepłacących podatki, rejestrował całkowitą liczbę mieszkańców ze wszystkich czterech kast w każdej wsi, a także prowadził dokładne zestawienia liczby rolników, pasterzy, kupców, rzemieślników, wyrobników, niewolników, zwierząt dwunożnych i czworonożnych. Ponadto ustalał zasoby złota, wolnej siły roboczej, myta i grzywien, które można zebrać z każdego domu.
statystyka – Francja ustanowiła Centralny Urząd Statystyczny w roku 1800 jako pierwszy tego rodzaju urząd na świecie.
statystyka – W Wielkiej Brytanii w 1834 roku powstało Królewskie Towarzystwo Statystyczne (pod początkową nazwą: Londyńskie Towarzystwo Statystyczne). Wtedy już statystykę uważano za „fakty odnoszące się do ludzi, możliwe do przedstawienia w postaci liczb, w wystarczająco zwielokrotnionej ilości, sygnalizujące prawa ogólne”.
Statystyka – Na statystykę matematyczną, jako zespół metod służących do analizy danych, też można spoglądać z różnych punktów widzenia.
Można ją traktować jako naukę w tym sensie, że ma swoją własną tożsamość z dużym repertuarem technik wywodzących się z pewnych zasad podstawowych i jest to teoretyczny aspekt statystyki. W tym zakresie tworzona jest teoria statystyki i teoretyczne rozwiązania konkretnych problemów. Tak jak cała matematyka, statystyka wykorzystuje rozumowanie dedukcyjne.
Natomiast w zakresie zastosowań statystyki do rozwiązywania zadań praktycznych można ją traktować z jednej strony jako technikę w tym sensie, że metodologię statystyczną można wbudować w każdy działający system.
Metody statystyczne można również wykorzystywać do kontrolowania, redukowania i uwzględniania niepewności, a przez to do maksymalizowania efektywności działania osób i instytucji, zaś z drugiej strony jako sztukę, ponieważ jej metodologia, która zależy od rozumowania indukcyjnego, nie jest w pełni skodyfikowana ani wolna od kontrowersji. Skłanianie liczb, by „same mówiły”, zależy od wprawy i doświadczenia statystyka.
Powyżej zostało użyte pojęcie rozumowania indukcyjnego. Ogólnie rozumowanie indukcyjne to decydowanie o przesłankach, gdy dysponujemy pewnymi ich następstwami.
Jest to rozumowanie, które umożliwia podejmowanie decyzji o świecie rzeczywistym, wykorzystując niepełne lub wadliwe informacje.
Pełne informacje są praktycznie niemożliwe do zdobycia, gdyż w celu ich uzyskania należałoby przebadać np, całą populację Polski. Również rzetelność zebranych informacji nigdy nie jest stuprocentowa. Wszelkie badania są wykonywane przez ludzi za pomocą odpowiednich narzędzi, mogą to być narzędzia pomiarowe albo testy psychologiczne i bardzo rzadko możemy być do końca pewni, że żaden z uzyskanych wyników nie jest obarczony pewnym błędem, niekoniecznie zresztą zamierzonym.
Wnioskowanie indukcyjne jest procesem logicznym, w którym uogólniamy przypadek szczególny. Tworzymy w ten sposób nową wiedzę, ale jest ona obarczona niepewnością z powodu braku pełnych informacji wykorzystanych w procesie indukcyjnym. Czy w związku z tym ta nowa wiedza jest nieprzydatna? Na początku XX wieku zrozumiano, że mimo iż wiedza uzyskana według jakiejkolwiek zasady uogólniania szczegółów jest wiedzą niepewną, staje się wiedzą użyteczną (zwróćmy uwagę: wiedzą użyteczną, a nie wiedzą pewną), jeśli potrafimy wyrazić ilościowo odpowiadającą jej niepewność (Rao, 1994). Jeśli zatem musimy podejmować decyzje w warunkach niepewności, to nie możemy uniknąć popełnienia błędów.
Fakt, iż podejmujemy decyzje przy braku pełnej informacji, leży u podstaw wszystkich metod statystycznych. Podejmowane przez nas decyzje mogą być zatem decyzjami błędnymi, lecz jednocześnie będziemy zawsze starali się określić (oszacować z góry) ryzyko (prawdopodobieństwo) podjęcia błędnej decyzji.
W Metodolog.pl dostarczamy rozwiązania związane z zaawansowaną analityką statystyczną, pomocą w analizach, algorytmami, metodologią, a także wykraczające ponad przeciętny poziom generowanie kodu (wykorzystujemy języki R, Fortran i Python). Nasze usługi związane z tematem analiz które pokrywają większość obszarów nauki (statystyczne testowanie hipotez i teorii), techniki (modelowanie i wizualizacja danych) oraz biznesu (uczenie maszyn i rozwiązania wspierające decyzje, aplikacje, dashbouardy itp). Dzięki naszym opracowanym programom statystycznym które opierają się zwalidowane naukowo rozwiązania, jesteśmy w stanie dostarczać ogrom raportów statystycznych, wizualizacji i treści. Bardzo często nasi klienci otrzymują od nas więcej niż oczekiwali w niesamowitej jakości, czasie i budżecie. Analizy statystyczne w naszej firmie są tym, czego poszukuje większość klientów poszukujących wsparcia naukowego w badaniach, analizie i organizacji danych. Niezależnie, od tego czy nasi klienci są studentami, doktorantami, profesorami, biznesmenami, wynalazcami, czy osobami szukającymi rozwiązań które poprawią im codzienne funkcjonowanie, to w nasze naukowe usługi i dbanie o sukces klienta oraz jego projektu, są dla nas ważne tak samo jak nasze własne projekty.
Analizy Statystyczne w Nauce na Poziomie Akademickim
Analiza statystyczna jest ważnym narzędziem dla naukowców na poziomie akademickim, ponieważ pozwala im na przeprowadzanie badań naukowych i wyciąganie wniosków z danych. Może być stosowana do wielu celów, takich jak:
Testowanie hipotez: Analiza statystyczna pozwala naukowcom na testowanie różnych hipotez na podstawie danych.
Modelowanie danych: Analiza statystyczna pozwala naukowcom na tworzenie modeli danych, co umożliwia przewidywanie przyszłych wyników lub zjawisk.
Określanie związków między zmiennymi: Analiza statystyczna pozwala naukowcom na określenie, czy istnieje związek między dwoma lub więcej zmiennymi.
Ocena skuteczności leczenia: Analiza statystyczna może być używana do oceny skuteczności różnych metod leczenia.
Przeprowadzanie badań ankietowych: Analiza statystyczna jest często stosowana w badaniach ankietowych, aby określić, jakie są poglądy lub preferencje danej grupy ludzi.
Ocena jakości produktów lub usług: Analiza statystyczna jest stosowana w celu oceny jakości produktów lub usług, np. poprzez przeprowadzanie badań satysfakcji klientów.
Analiza statystyczna jest ważnym narzędziem dla naukowców, ponieważ pozwala im na wyciąganie wniosków i podejmowanie decyzji na podstawie danych, co przyczynia się do rozwoju wiedzy i postępu naukowego.
Obszary naukowe analizy statystycznej
Analiza statystyczna jest szeroko stosowana w wielu dziedzinach nauki, takich jak:
Nauki społeczne: Analiza statystyczna jest szeroko stosowana w naukach społecznych, takich jak socjologia, psychologia, polityka, ekonomia i inne, w celu badania zachowań ludzi i grup społecznych.
Medycyna: Analiza statystyczna jest ważnym narzędziem w medycynie, gdzie jest stosowana do oceny skuteczności leczenia, badania wpływu czynników na zdrowie i innych zagadnień związanych z zdrowiem.
Ekonomia: Analiza statystyczna jest ważnym narzędziem w ekonomii, gdzie jest stosowana do badania trendów rynkowych, oceny skuteczności różnych strategii biznesowych i innych zagadnień związanych z gospodarką.
Nauki przyrodnicze: Analiza statystyczna jest również stosowana w naukach przyrodniczych, takich jak biologia, chemia i inne, w celu badania zjawisk zachodzących w przyrodzie i wyciągania wniosków na ich podstawie.
Inżynieria: Analiza statystyczna jest również stosowana w inżynierii, gdzie jest używana do oceny jakości produktów i procesów produkcyjnych oraz do badania wpływu różnych czynników na działanie systemów technicznych.
Analiza statystyczna jest ważnym narzędziem dla naukowców i badaczy z wielu dziedzin, ponieważ pozwala im na przetwarzanie i interpretowanie danych za pomocą różnych metod statystycznych i wyciąganie wniosków na ich podstawie.
Analizy statystyczne w biznesie
Analiza statystyczna jest ważnym narzędziem dla przedsiębiorców i menedżerów, ponieważ pozwala im na podejmowanie trafnych decyzji biznesowych na podstawie danych. Oto kilka przykładów zastosowań analiz statystycznych w biznesie:
Ocena skuteczności marketingowych: Analiza statystyczna może być używana do oceny skuteczności różnych działań marketingowych, takich jak reklamy, kampanie e-mailowe itp.
Badanie rynku: Analiza statystyczna może być używana do badania preferencji klientów i trendów rynkowych, co pomaga w podejmowaniu decyzji dotyczących produktów lub usług.
Ocena efektywności procesów produkcyjnych: Analiza statystyczna może być używana do oceny efektywności procesów produkcyjnych i identyfikacji możliwych obszarów do poprawy.
Analiza kosztów: Analiza statystyczna może być używana do analizy kosztów i określenia, gdzie można zaoszczędzić pieniądze.
Ocena jakości produktów lub usług: Analiza statystyczna może być używana do oceny jakości produktów lub usług poprzez przeprowadzanie badań satysfakcji klientów.
Analiza statystyczna jest ważnym narzędziem dla przedsiębiorców i menedżerów, ponieważ pozwala im na podejmowanie trafnych decyzji biznesowych na podstawie danych i umożliwia lepsze zrozumienie rynku i potrzeb klientów.
Jakość analiz statystycznych
Jakość analiz statystycznych jest ważna, ponieważ wpływa na wiarygodność i przydatność wyników. Oto kilka czynników, które mogą wpływać na jakość analiz statystycznych:
Poprawność metod: Ważne jest, aby dobrać odpowiednie metody statystyczne do rodzaju danych i celu analizy.
Jakość danych: Jakość danych jest ważna, ponieważ wpływa na wiarygodność wyników. Ważne jest, aby zadbać o to, aby dane były kompletne i dokładne.
Poprawność interpretacji: Ważne jest, aby prawidłowo interpretować wyniki analizy statystycznej i unikać błędów w interpretacji.
Transparentność: Ważne jest, aby przedstawić wyniki analizy statystycznej w sposób jasny i zrozumiały dla odbiorców.
Poprawność implementacji: Ważne jest, aby zadbać o poprawność implementacji metod statystycznych i unikać błędów technicznych w kodzie.
Zadbanie o jakość analiz statystycznych jest ważne, ponieważ wpływa na wiarygodność wyników i pozwala na podejmowanie trafnych decyzji na podstawie danych.
Jaką pomoc w analizach statystycznych oferuje Metodolog.pl?
Nasi klienci i przyjaciele mają się u nas bardzo dobrze, pomoc w analizach statystycznych jaką oferujemy jest bogata i raczej nieograniczona (przy optymalnym czasie i budżecie). Jeśli chcesz spędzić trochę czasu na czymś dobrym, po prostu dołącz do nas mailowo lub telefonicznie. Wykonujemy ekspertyzy w następujących tematach:
• Pisanie programów i kodów statystycznych w R/R Shiny, Fortran i Python.
• Wielopoziomowe modelowanie SEM w pakiecie "lavaan" oraz "xxM"
• Modele równań strukturalnych CB (modelowanie oparte na kowariancji) i PLS (modelowanie zorientowane na przewidywanie metodą częściowych najmniejszych kwadratów)
• Analizy konfirmacyjne, mediacyjne, moderacyjne i pochodne
• Modelowanie regresji wielopoziomowej (również przy różnych założeniach dystrybucyjnych)
• Wizualizacje danych w pięknym stylu w "ggplot2", "plotly" oraz "diagrammer"
• Automatyzacja analiz statystycznych i systemów ich raportowania
• Instalacja uczenia maszynowego i silników algorytmicznych w internecie lub maszynach
• I różne analizy statystyczne zorientowane na śledzenie zmian w czasie (np. modele szeregów czasowych), analizę zmian w powtarzanych pomiarach i wnioskowanie ze złożonych projektów eksperymentów czynnikowych (w ramach różnych efektów wariancyjnych i ich interakcji)
• Projektowanie badań ilościowych, eksperymentalnych, budowanie narzędzi psychometycznych, pomiarowych, skal i miarek
• Weryfikacja prostych i złożonych hipotez prostymi testami statystycznymi lub testami wieloczynnikowymi
• I wiele innych, bo ciągle się uczymy i wciąż jesteśmy wygłodniali nowej wiedzy
Potrzebujesz analiz statystycznych lub konsultacji on-line ze specjalistą statystykiem lub programistą R?
Projekty statystyczne w nauce i biznesie to poważne przedsięwzięcia od nich zależą przyszłe zarobki i reputacja badacza w środowisku naukowym. Nie oczekujemy, że podejmiesz z nami współpracę od razu. Wstrzemięźliwość i zimna ocena kompetencji oraz kontaktu z firmą to kluczowe cechy dobrego wyboru specjalisty wykonującego analizy statystyczne, dlatego zachęcamy do niezobowiązujących i darmowych konsultacji. Kliknij by zobaczyć jak one u nas wyglądają KLIK
Kontakt z Metodolog.pl
Skontaktuj się z nami, a na pewno pomożemy Ci w obliczeniach, przedyskutujemy wątpliwości i wstępnie ocenimy Twój projekt. Nasz zespół specjalistów z różnych dziedzin posiada wiedzę i doświadczenie w przeprowadzaniu analiz statystycznych w interdyscyplinarnych kontekstach nauk empirycznych i w zdywersyfikowanych polach obszarów biznesu oraz rynku. Wykonujemy specjalistyczne obliczenia statystyczne do projektów z poziomu akademickiego oraz realizujemy większość prac związanych z wielowymiarową analizą klienta, sprzedaży produktu, prognozowaniem i ogólnie pojętego przetwarzania danych rynkowych.
P.S. Jeśli chcesz, możesz zapisać się na nasze darmowe szkolenia. Rzuć okiem na to co akurat przygotowujemy dla naszych znajomych i klientów klik
Czym się zajmuje statystyk?
Po pierwsze, statystyk w naszym zespole jest zorientowany na nawiązanie ciepłej (choć nie zawsze jest to możliwe) i profesjonalnej (to jest akurat nasz standard) relacji z klientem. Wierzymy, że niezmącona wymiana informacji pomiędzy ekspertem statystyki i drugą stroną jest kluczonym elementem który wpływa na tempo realizacji projektów i sukces projektu. Co więcej, statystyk w Metodolog.pl w kontekście złożonych projektów, nowych lub takich które polegają na odkrywaniu lub modernizacji znanych rozwiązań jest skupiony na szybkim i skutecznym uczeniu się nowych rzeczy np. zrozumieniu nowych metod statystycznych, algorytmów, logiki zmienności zjawisk i ich oceny. Statystyk zajmuje się ciągłym uczeniem się, myśleniem problemowym, i testowaniem tego w praktyce analitycznej. Można też powiedzieć, że dzisiejszy statystyk mający radzić sobie z współczesnymi wyzwaniami musi znać jakiś język programowania. Tym czym zajmuje się dziś statystyk i gwałtowność zmian jaka rządzi światem nauki i biznesu, wymusza na takiej osobie znajomość metod dostosowywania, automatyzacji, optymalizacji pracy komputerów i systemów informatycznych, a to wymaga umiejętności pisania w języku zrozumiałym dla maszyn.
Jak się liczy dane statystyczne?
Dane statystyczne liczy się na wiele sposobów. Niemniej, najważniejsza w liczeniu danych statystycznych jest jedna rzecz, są to wnioski. Wyciągnięcie pożądanych wniosków zawęża wykorzystanie analiz statystycznych do konkretnych danych i sposobów ich liczenia. Liczeniem danych statystycznych zajmują się dobre komputery, serwery lub pewnego rodzaju systemy rozproszone. Dzięki cyfryzacji i rozwojowi nauk o danych (ang. data science) pojawiły się niesamowite możliwości analizy danych statystycznych. W obliczu tego, trudno odpowiedzieć na takie pytanie. Zazwyczaj metody liczenia danych statystycznych wyznacza się względem wniosków do wyciągnięcia. Ewentualnie jest to wyznaczane problemem do rozwiązania. Bogactwo możliwości jakie dają zaawansowane algorytmy statystyczne pozwalają w zasadzie przeliczyć każde dane i rozwiązań większość problemów naukowych i problemów życia codziennego. Osobom zainteresowanym chętnie odpowiemy na te pytania.
Na czym polega statystyka?
Statystyka polega na analizie danych masowych. Tak na prawdę można powiedzieć, że statystyka jest nauką dotyczącą analizy zmienności i identyfikacji jej źródeł. Podejścia statystyczne starają się wnioskować na temat populacji względem próbki. Niemniej, nie jest to jej uniwersalny cel. W badaniach naukowych statystyka polega na takim wykorzystaniu metod obliczeniowych, by potwierdzić lub zakwestionować losowość badanych zjawisk. W tym przypadku statystyka ma na celu weryfikacje prawdziwości rozumowania badacza i prawidłowości stosowanych przez niego metod badawczych. W przypadkach biznesowych lub technicznych statystyka ma na celu sterowanie procesami, pamiętaniem, rozpoznawaniem i klasyfikowaniem. Ogólnie można powiedzieć, że ma imitować inteligencję człowieka, czyli jest pewnego rodzaju sztucznie wymodelowaną inteligencją.
Jakie korzyści wynikają ze współpracy ze statystykiem?
Odpowiedź na to pytanie jest prosta, ale możemy zadać inne, podobne pytanie: Dlaczego relacje z naszym mechanikiem samochodowym są tak ważne? Nasze relacje z innymi specjalistami (oczywiście musimy założyć, że mówimy o prawdziwych, zaangażowanych i szczerych fachowcach) są ważne, ponieważ możemy skorzystać z ich bogatego doświadczenia i historii projektów. Niemniej jednak ekspercka pomoc i nawiązany kontakt ze statystykiem metodologiem są ważne z dwóch konkretnych powodów:
1. Ogólnie rzecz biorąc, statystyk metodolog zna wiele metod pomiaru, metod zagnieżdżania danych, filozofii przyczynowo-skutkowych oraz metod eksperymentalnych w różnych układanych badawczych i strukturach danych (np. powtarzane pomiary i eksperymenty czynnikowe, dane tekstowe, macierzowe itp.). Warto zauważyć, że wcześniejsze spotkanie z ekspertem może zmniejszyć ryzyko niepowodzenia w kontekście badawczym. Wyraźnym przykładem jest pomiar zmiennej zależnej w eksperymentach psychologicznych. Czasami ta kluczowa zmienna jest mierzona jednym zachowaniem lub jednym elementem testowym. W konsekwencji może to prowadzić do stronniczych lub po prostu słabych wyników.
2. Utrzymywana relacja ze statystykiem metodologiem jest ważna, ponieważ zarówno specjalista, jak i klienci rozwijają się w swoich specjalizacjach. Taka sytuacja jest korzystna dla obu stron. Metodolog może wdrożyć nowo poznaną metodę statystyczną dla klientów, a ci drudzy mogą osiągnąć większy sukces w bardzo konkurencyjnej dziedzinie jaką jest nauka lub w dynamicznym kontekście biznesowym. Na przykład w 2015 roku pojawiła się krytyka modelu opóźnionego krzyżowo (ang. Cross Lagged Panel Model) w projektach eksperymentalnych z powtarzanymi pomiarami. Główne obawy tej krytyki dotyczyły stabilności wyników w czasie, która nie jest traktowana jako stały czynnik indywidualny (zgodnie z pojęciem stabilności wewnątrzjednostkowej i zróżnicowania interpersonalnego). W tym kontekście stare dane zyskują nowe życie, ponieważ od teraz mogą być analizowane jako efekt przeniesienia z wykorzystaniem techniki losowych interceptów (ang. rondom intercept cross-lagged models).
Analizy statystyczne w nauce – Naukowe wsparcie Metodolog.pl
Analizy statystyczne w nauce – Przyjrzyjmy się obrazkowi poniżej, co widzimy? Obrazek przedstawia czas żniw. Widzimy kombajn, który jednocześnie kosi zboże, młóci je i przekazuje na przyczepę*. Możemy się domyślać jedynie, że ciągnik zawiezie zboże do zaprzyjaźnionego młyna lub przetwórni, a tam zrobią z ziarnem coś pożytecznego. Czytelnik może się zastanawiać w jakim celu jest przytoczony ten obrazek oraz po co ta cała historia? Odpowiedź jest bardzo prosta, chodzi o pewną analogię między zbieraniem zboża, a zbieraniem danych. Ciężko jest o lepsze porównanie, chociażby ze względu na realność tych dwóch czynności oraz trud wkładanej w nie pracy. Rolnicy, podobnie jak naukowcy, muszą strategicznie planować wszystkie swoje kroki i działania, polegające na osiągnięciu pewnego celu jakim są żniwa. Rolnik oczekuje owocnych zbiorów, a naukowiec spodziewanych wyników potwierdzających jego przewidywania.
Po co to wszystko?
Eksperymentator, podobnie jak rolnik, musi skrupulatnie i dokładnie organizować swoją pracę by nie narazić się na błędy, które będą cofać lub hamować stawiane kroki badawcze. Chcielibyśmy poradzić naszym klientom nawiązanie współpracy przed wykonaniem badań. Dzięki konsultacjom, metodologicznym i statystycznym, można ograniczyć ryzyko napotkania trudności związanych z analizą statystyczną danych i wykorzystaniem odpowiednich metod obliczeniowych dla danego problemu badawczego. Warto zadbać, w czasie planowania lub realizacji badań, o dobrego dostawcę rozwiązań naukowych, tak jak w przypadku rolnika dbającego o odbiorcę jego roślin.
Analizy statystyczne w nauce – woda na młyn nauki.
Analizy statystyczne w nauce są czymś, co ukształtowało nasze sposoby myślenia o zbieraniu danych i kierunki postępu naukowego. Warto więc przyjrzeć się temu zagadnieniu nieco bliżej. Jak już wspominaliśmy we wcześniejszym wpisie „o analizach statystycznych pierwszej i drugiej generacji”. Co chwila pojawiają się nowe metody obliczeniowe i analizy statystyczne nad którymi bardzo ciężko nadążyć. Nowe metody obliczeniowe pojawiają się co chwila, wystarczy wymienić ogólnoświatowe forum CrossValidated na którym codziennie są wymieniane informacje o nowych funkcjach i metodach statystycznych, dostępnych w bibliotekach i skryptach pakietu R. Dzięki tak szybkiemu postępowi w dziedzinie statystyki, naukowcy i eksperymentatorzy mogą wykorzystywać nowe i ulepszone analizy statystyczne do dokładniejszej weryfikacji wyników swoich badań.
Zachęcamy do współpracy wszystkie osoby, które chcą oddać swoje dane do profesjonalnej analizy. Nasze analizy statystyczne w nauce zadowolą każdego eksperymentatora.
*Poza tym istnieje duże prawdopodobieństwo, że kombajn automatycznie zostawia po sobie snopki.
Odkąd Joreskog w 1978 roku wprowadził bazujące na kowariancji modelowanie równań strukturalnych (SEM), to technika ta uzyskała znaczne zainteresowanie badaczy. Jakkolwiek, przewaga LISRELa, pewnie najlepiej znanego oprogramowania do wykonania tego typu analizy prowadzi do stwierdzenia faktu, że nie wszyscy badacze są świadomi alternatywnej techniki dla SEM, takiej jak cząstkowe najmniejsze kwadraty (ang. PLS – partial least squares). Technika ta jest wszechstronna kiedy konstrukty są mierzone przez bardzo dużą ilość wskaźników i gdzie modelowanie równań strukturalnych metodą największej wiarygodności osiąga swój limit. W tym wpisie pominiemy matematyczne detale tej analizy i skupimy na ogólnym zarysie tego zagadnienia.
Analizy statystyczne – pierwsza generacja.
Pierwsza generacja technik statystycznych, takich jak podejścia oparte na regresji (wielozmiennowe analizy regresji, analizy dyskryminacyjne, analizy wariancji itd.) oraz analizy czynnikowe, czy analizy skupień, przynależą do rdzenia zestawu statystycznych narzędzi które należą do identyfikowania i potwierdzania teoretycznych hipotez bazujących na analizie statystycznej danych empirycznych.
Wielu badaczy w różnych dyscyplinach naukowych stosowało te metody do generowania odkryć. Metody te znacznie ukształtowały sposób w jakim widzimy dziś świat (np. teoria inteligencji została utworzona na podstawie analizy czynnikowej).
Wspólnym mianownikiem dla tych wszystkich metod jest, że dzielą one trzy ograniczenia nazywane:
postulatem prostej struktury modelu (co najmniej w przypadku podejść regresyjnych)
założeniem, że wszystkie zmienne mogą być rozważane jako obserwowalne
przypuszczeniem, że wszystkie zmienne są mierzone bez błędu, co może ograniczać ich aplikowanie w wielu badawczych sytuacjach
W celu pokonania ograniczeń pierwszej generacji technik statystycznych coraz więcej autorów zaczęło używać modelowania równań strukturalnych (SEM) jako alternatywy. W porównaniu do podejść regresyjnych, które analizują tyko jedną warstwę powiązania pomiędzy niezależną i zależną zmienną w tym samym czasie, SEM jako technika drugiej generacji, pozwala na jednoczesne modelowanie związków pomiędzy wieloma niezależnymi i zależnymi konstruktami, a także zmiennymi mediującymi i moderacyjnymi. Tak więc w tym podejściu trudno jest rozróżnić zmienne zależne i niezależne, dlatego przyjmuje się, że zmienną lub zmiennymi zależnymi są zmienne które są wyjaśniane jako ostatnie w modelu.
Dodatkowe zalety modelowania równań strukturalnych (SEM)
SEM pozwala badaczowi konstruować nieobserwowalne zmienne mierzone przez wskaźniki (nazywane itemami, zmiennymi manifestującymi lub zmiennymi obserwowalnymi), a także jako jawny model pomiarowy błędów dla obserwowalnych zmiennych. Metoda ta pokonuje ograniczenia technik pierwszej generacji opisanych wcześniej i konsekwentnie daje badaczowi elastyczność do statystycznego testowania pomiarowych założeń wobec danych empirycznych (np. analiza konfirmacyjna lub analiza pełnego modelu pomiarowego, analiza trafności różnicowej (warto sprawdzić czemu to założenie jest jednym z najwazniejszych założeń w testowaniu modeli strukturalnych KLIK)
Dwa podejścia estymowania parametrów – Modelowanie równań strukturalnych metodą wariancyjną i kowariancyjną.
Ogólnie istnieją dwa podejścia estymacji parametrów modelu strukturalnego. Pierwsze nazywa się podejściem kowariancyjnym, a drugie podejściem opartym na wariancji. Podejście oparte na kowariancji próbuje minimalizować różnicę między kowariancją w próbce, a kowariancją proponowaną przez model. Niestety, ten typ analizy jest dosyć wymagający ze względu na oszacowywanie wszystkich parametrów modelu jednocześnie, a także konserwatywne kryteria oceny dopasowania danych do utworzonego modelu. Natomiast, podejście wariancyjne stara się maksymalizować zmienność zależnych zmiennych wyjaśnianych przez zmienne niezależne (zamiast odtwarzać empiryczną macierz kowariancji jak w podejściu kowariancyjnym), oszacowania w modelu są wykonywane krokowo w dwóch etapach. Podobnie jak każdy SEM, model PLS (partial least squares) zawiera strukturalną część która odzwierciedla związki pomiędzy zmiennymi latentnymi (inner model) i pomiarowymi komponentami, które pokazują jak zmienne latentne są powiązane z ich wskaźnikami (outer model). Kiedy użyć takie modelu PLS, a kiedy SEM-CB można zobaczyć tutaj.
Zalety metody SEM, w szczególności metody PLS.
Zaletą modelowania równań strukturalnych metodą PLS jest możliwość odzwierciedlania reflektywnych i formatywnych zmiennych w testowanych modelach strukturalnych, które są budowane z dużej ilości zmiennych obserwowalnych. Ponad to, dzięki takim możliwościom estymacji modelu strukturalnego błąd pomiarowy jest uwzględniany w analizie. Z tego względu przy tego typu konstrukcjach, oszacowania współczynników wpływu i wyjaśnionej wariancji są bardziej zbliżone do rzeczywistych niż w przypadku modeli formatywnych lub zmiennych mierzonych bez błędu.
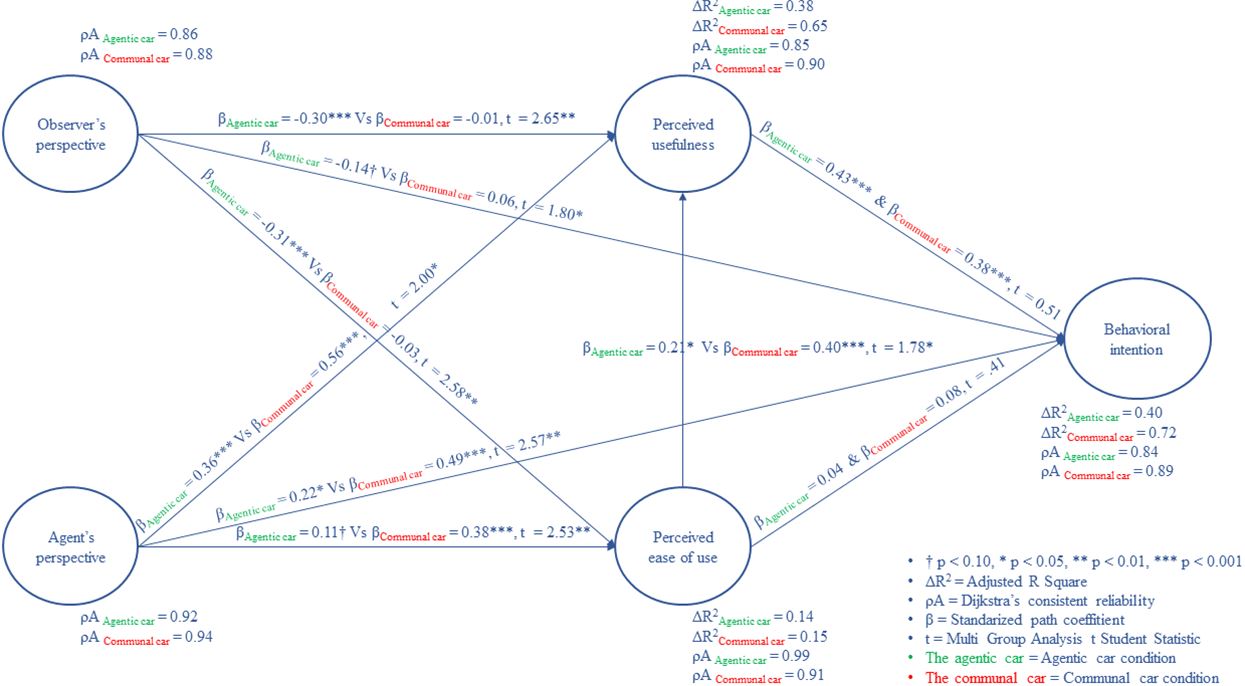
Żeby zobaczyć naukowo udowodnione prawidłowości akceptacji technologii samochodów autonomicznych kliknij niżej żeby zobaczyć jak wykorzystałem do tego modelowanie równań strukturalnych w moim artykule naukowym KLIK lub – > https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0238714.
Więcej na temat modelowania CB i PLS można poczytać u championów tego obszaru:
Dijkstra, T. K., & Henseler, J. (2015). Consistent partial least squares path modeling. MIS Quarterly: Management Information Systems, 39(2), 297–316. https://doi.org/10.25300/MISQ/2015/39.2.02
Garson, G. D. (2016). Partial Least Squares: Regression & Structural Equation Models. In G. David Garson and Statistical Associates Publishing. Statistical Associates Publishing.
Hair, Joe F., Ringle, C. M., & Sarstedt, M. (2011). PLS-SEM: Indeed a silver bullet. Journal of Marketing Theory and Practice, 19(2), 139–151. https://doi.org/10.2753/MTP1069-6679190202
Hair, Joseph F., & Sarstedt, M. (2019). Factors versus Composites: Guidelines for Choosing the Right Structural Equation Modeling Method. Project Management Journal, 50(6), 619–624. https://doi.org/10.1177/8756972819882132
Henseler, J., Ringle, C. M., & Sarstedt, M. (2014). A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science, 43(1), 115–135. https://doi.org/10.1007/s11747-014-0403-8
Kock, N. (2015). Common method bias in PLS-SEM : A full collinearity assessment approach. 1–10.
Sharma, P. N., & Kim, K. H. (2012). Model selection in information systems research using partial least squares based structural equation modeling. International Conference on Information Systems, ICIS 2012, 1, 420–432.
Tarka, P. (2017). An overview of structural equation modeling: its beginnings, historical development, usefulness and controversies in the social sciences. Quality and Quantity, 52(1), 313–354. https://doi.org/10.1007/s11135-017-0469-8
Vinzi, V. E., Trinchera, L., & Amato, S. (2010). Handbook of Partial Least Squares (V. E. Vinzi, L. Trinchera, & S. Amato (eds.)). Springer. https://doi.org/https://doi.org/10.1007/978-3-540-32827-8
Metodolog.pl
Serwis korzysta z plików cookies. Dowiedz się więcej na temat Polityki cookies i możliwości zmiany ustawień cookies w Twojej przeglądarce. Korzystając z serwisu wyrażasz zgodę na używanie cookies, zgodnie z ustawieniami przeglądarki.






{kind=link}